
Network as a Service (NaaS) PlayBook
1. O&M NOC Introduction
The network operation center (NOC) is a functional team that specializes in monitoring, troubleshooting and responding to undesired events on a network which have a direct or potential impact on the networks availability and performance, or affecting end users. NOC services and responsibilities include, amongst others:
This module presents an introduction to the functions, processes and tools that operate within a NOC, and establishes guidelines for the NaaS operators to define the structure of their own NOC, customize the processes that will be implemented, evaluate and select the tools that will support the operation, and define the implementation model to be followed along with the dimensioning of the NOC team and facilities.
1.1 Module Objectives
This module will immerse the NaaS operator into the functions and processes of the NOC and will provide the necessary directions to define processes and resources and identify required systems for the NaaS operators NOC. The specific objectives of this module are to:
1.2 Module Framework
The module framework in Figure 1 describes the structure, interactions and dependencies among different NaaS operator areas.
Strategic plan & scope and high-level network architecture streams drive the strategic decisions to forthcoming phases. Operations & maintenance stream comes after network deployment to oversee and support the on-going operation of the network, supported by supply chain management.
The NOC is the heart of the operations & maintenance stream as it coordinates with the service operation center (SOC) and triggers actions on the field maintenance stream.
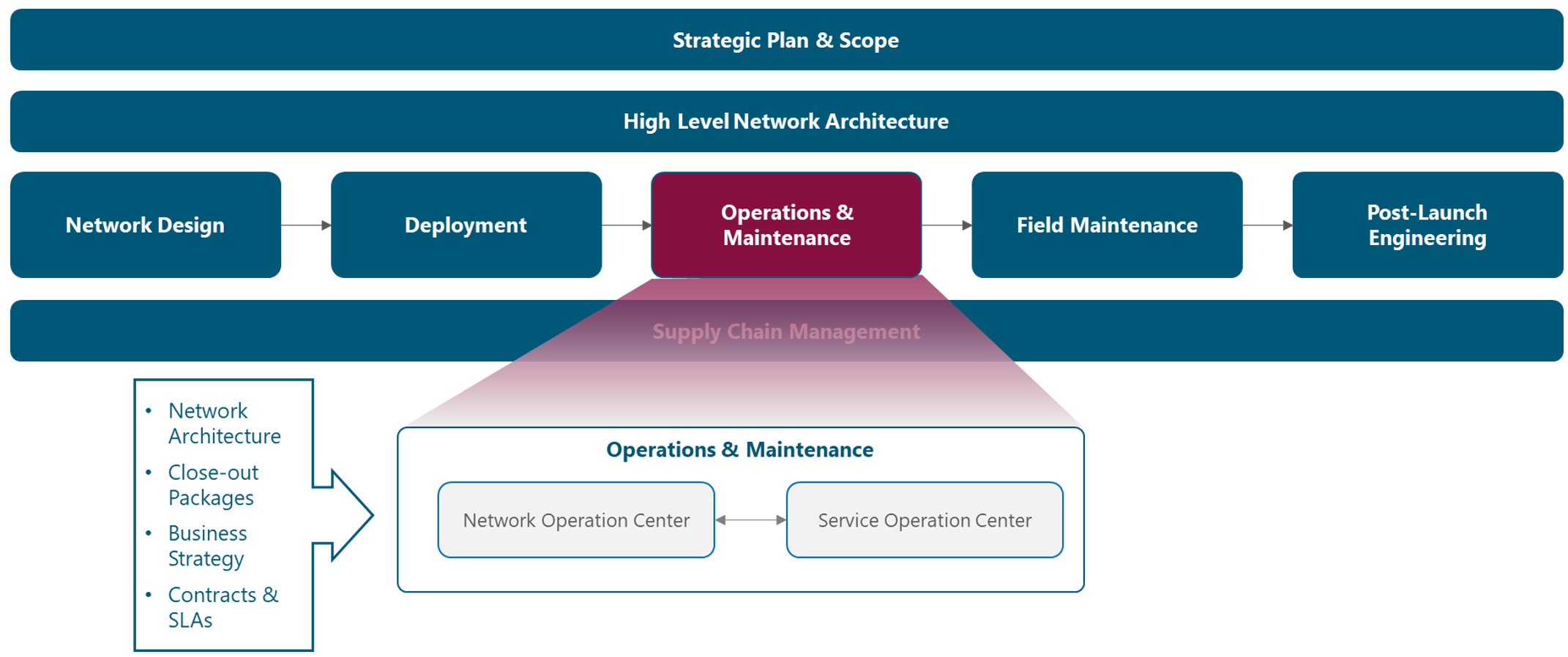
Figure 1 — Module Framework
Figure 2 presents a functional view of the NOC module where the main functional components are exhibited.
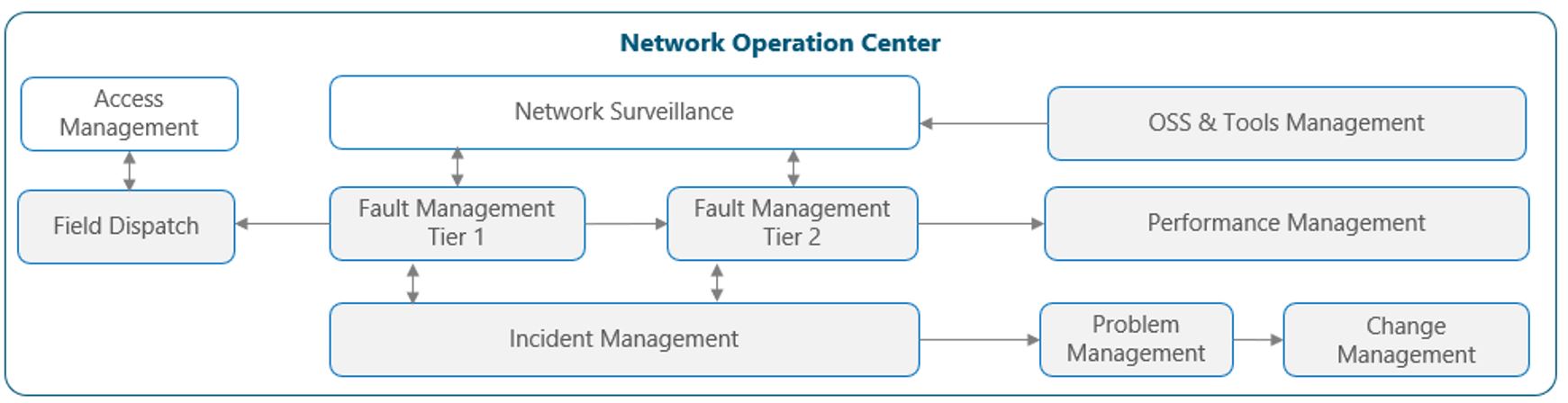
Figure 2 — Network Operations Center Functional View
The rest of the module is structured as follows: overview of fundamental concepts of the NOC is addressed in section 2. Then, each function and its processes are discussed in sections 3 and 4 of this module. Section 5 provides a high-level view on systems. Finally, section 6 discusses implementation issues including staffing and facility dimensioning.
2. NOC Fundamentals
This section provides an overview of the NOC, including the organization structure and the scope for each team highlighting the relevance and potential impact for NaaS operators.
2.1 NOC Overview
The NOC is the entity responsible for monitoring and responding to any alarm or unwanted condition that may have an impact on the network, potentially affecting end customers. The NOC can be considered the first line of defense against any disruption on the network. The NOC enables centralized supervision, control and maintenance of all equipment and network domain elements on a NaaS operator network.
A NOC responds to deviations from a normal network status like:
The NOC will analyze the situation, perform troubleshooting, engage necessary fix agents, and follow up until the network has restored to the previous, normal condition.
The main responsibilities of the NOC may include:
The main responsibility of the NOC is to react as quickly as possible to any problem that may arise on the network, getting out in front of issues and fixing them before they impact their end customers or other MNO end customers. The benefits that a NOC organization brings to NaaS operators are:
Additionally, the NaaS operators NOC must consider the implication of having as customers one or several MNOs, each of them with their respective NOCs. The coordination between the different NOCs will generate additional inputs and steps on the NOC processes, which will be discussed in section 4.
Coordination must be established between the NOC entities. The collaboration can be implemented at different levels such as:
These levels of collaboration need to be established between the NaaS operator and the customer MNOs to efficiently combine their efforts. The different interactions between the NaaS operator NOC and the NOCs from other MNOs will be explained in detail in section 6 and is graphically represented in Figure 3.
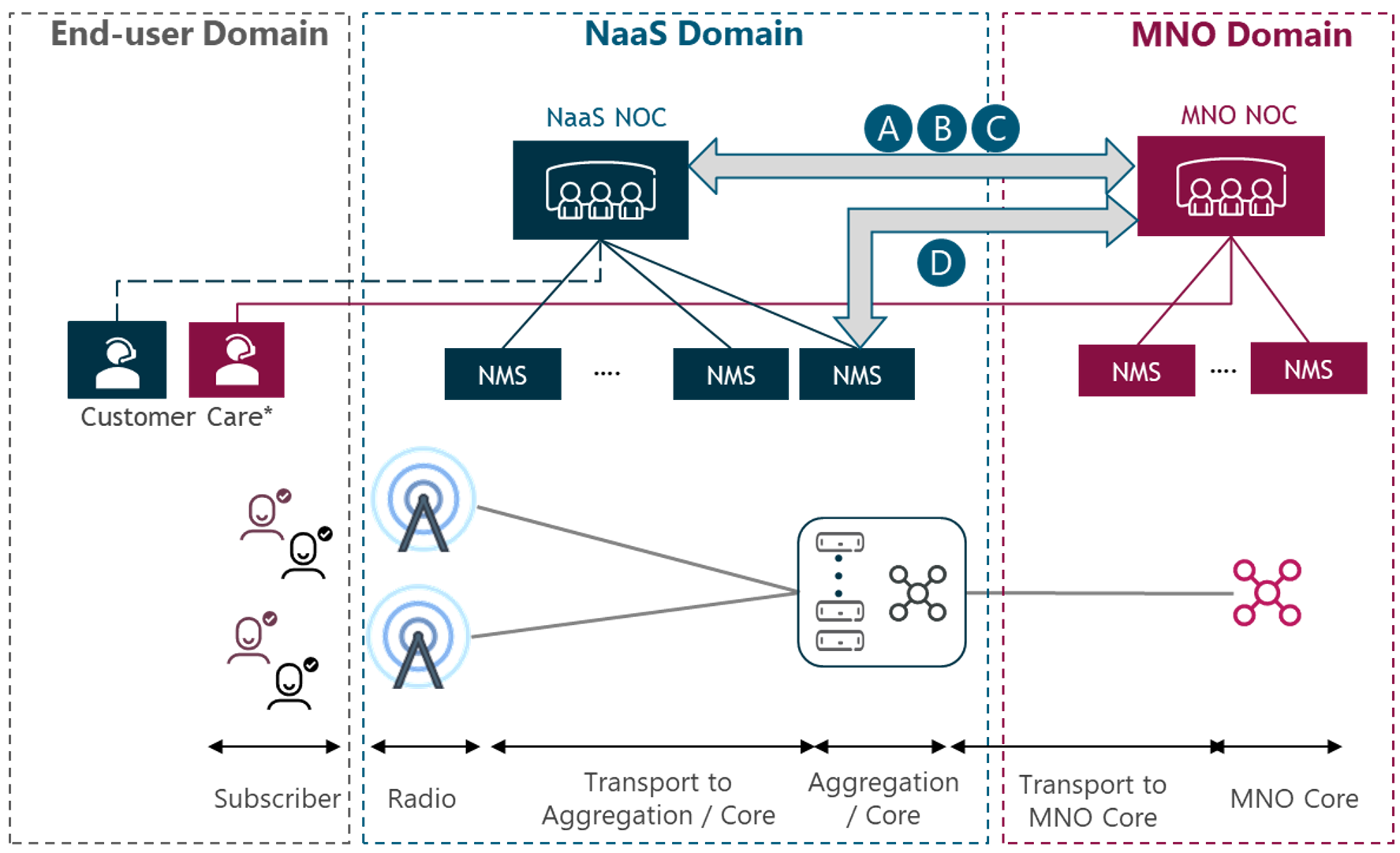
Figure 3 — Network Operation Center Functional View
It should be noted that the customer care from the NaaS Operator should only be present when the NaaS Operator manages their own end-users (i.e., subscribers). This approach is out of the scope of this module.
2.2 NOC Organization
From a functional view, the NOC includes the following services:
These functions will be covered in-depth on Section 3 of this module, where appropriate guidance will be provided for the NaaS operator to define the structure that best matches the intended scope of the organization.
The functions above are integrated into processes, which are executed by the NOC. From a process view, the NOC includes the following responsibilities:
These processes will be covered in Section 4 of this module. The NaaS operator will be presented with alternatives to customize the processes according to their requirements and capabilities. Its important to consider that the NaaS operator processes will have inputs and outputs from/to NOCs from customer MNOs. These collaborations imply variations to the processes, based on the business and operational model in addition to the responsibilitys division between the NaaS and other MNOs. Guidance to define the business and operational model along with the responsibility split is provided in section 6.
The diverse teams working within the NOC organization coordinate their efforts in order to prevent or minimize any unplanned interruption on the network, or a reduction/degradation in the quality of the service delivered to the end-user. The main roles and responsibilities are summarized below:
This module will enable NaaS operators to examine the different scenarios and to choose which functions could be merged in their operation according to their scope.
3. NOC Functions
This section defines the NOC from a functional level, focusing on its vital aspects and the configuration possibilities for the NaaS operator.
3.1 NOC Functions Overview
In the following subsections, the description for each function of the NOC is presented along with an analysis of the key metrics and the relevance/need for each function.
3.1.1 Network Surveillance
Network surveillance is the first and most vital function that is supported by a NOC. NOC staff performs continuous monitoring of all the network elements, using available tools like a network monitoring system (see Network Monitoring Architecture module) or via the different element management systems (EMS) provided by equipment vendors. In addition, the NaaS Operator must grant limited access to these systems to the MNO NOCs to monitor only the elements of the network related to their users.
For those network or performance alarms detected, NOC staff will conduct preliminary filtering (such as correlation, alarms due to planned work, etc.), open the corresponding trouble ticket (TT), monitor the alarm warnings, categorize/prioritize the alert severity and handle the problem escalation according to defined procedures. During this stage, a constant communication between the tenant NOCs and the NaaS operator NOC will lead to a better categorization, filtering and avoidance of unnecessary TT.
Network surveillance function typically includes the following activities:
Network surveillance is the most critical function in the NOC. Since this is the function that monitors incoming alarms and events on the network, it is the first-point entry for network status and enables responses in a timely manner which translates into an overall improvement of restoration times.
Typical metrics used to evaluate the performance of this function are:
3.1.2 Fault Management Tier 1
Fault management (tier 1) function includes fault analysis, first-level corrective maintenance, End-to-End (E2E) fault management and incident management. The purpose is to filter and solve most of the cases without on-site intervention or additional resources within the timeframe specified by service levels.
Fault management (Tier 1) functions include the following tasks:
It is imperative that the NaaS operator NOC and the NOCs from customer MNOs have constant communication when issuing TT to avoid duplicity and waste of technical resources. The best approach is through a direct connection of the ticketing systems of the respective NOCs, but since compatibility may be an issue, a primitive method could be used such as phone calls to open TT from customer to NaaS Operator.
The fault management function is the second most vital function within a NOC. The group that executes this function assures that alarms that were acknowledged in the previous step are worked and eventually resolved, contributing to the overall network performance and as a result, having an impact on customer satisfaction.
The most common metrics used to evaluate this function are:
Similarly, it is recommended that the fault management systems from the NaaS operator and customer MNOs work together or be interconnected to minimize communication time. One implementation option is to connect the fault management systems from the NaaS operator and customer MNOs using open interfaces. In this case, the NaaS operator must limit the MNOs access to prevent exposing the complete network metrics or KPIs due to privacy issues.
3.1.3 Fault Management Tier 2
Fault management tier 2 resolves the network faults escalated by fault management tier 1 or first-line maintenance teams also known as field technicians. If a fault cannot be solved by tier 2 staff, it will be escalated to tier 3 support which for most NaaS operators will consist of requesting direct support from equipment vendors.
As the tenant NOCs may have more significant experience in the troubleshooting for mobile networks, an alternative is to rely on the tier 2 and/or tier 3 from them. This would decrease the required budget for the NaaS operator NOC and shorten the implementation time. However, an agreement must be reached first with customer MNOs. This tactic will be further reviewed in sections 6.4 and 6.5.
The main activities are:
This specific function is assigned to a group of people whose expertise is broader and deeper than the fault management tier 1 team. This team usually works on cases that the previous team was not able to diagnose, escalates cases to tier 3 support (vendor support) and supervises the diagnosis, troubleshooting and resolution of high severity scenarios.
Having a fault management tier 2 team helps the organization by lowering resolution times for complex cases. The absence of this team implies that cases need to be escalated to vendor support directly by the fault management tier 1 team, thus increasing the time and cost to resolve the incident.
Generally used metrics to evaluate this function are:
3.1.4 Performance Management
This function consists of identifying performance-related issues for network elements and ensuring they are correctly prioritized and managed until proper resolution. Performance management includes the analysis and reporting of network quality measures.
The main activities include:
The performance management team works on performance-related scenarios that are not related to break/fix cases. This function frequently works with engineering/optimization teams to verify, validate, and resolve performance-related issues. These issues are categorized and treated according to the SLA agreed with the affected MNOs (for example, response times, escalation times and priorities). When possible, it is a good practice to target the tightest agreed SLA in the network; in any case, network KPIs should be reported on a per-MNO basis.
The most common metrics used to evaluate this function are:
3.1.5 OSS & Tools Management
OSS & tools team is the administrative entity for all OSS, EMS and NOC tools that are deployed for network management. OSS management includes the analysis and reporting of OSS quality measures.
The main activities include:
The OSS & tools function aids the different functions of the NOC with daily tasks as user administration which includes account or permission details, access rights OSS management including routine maintenance, health checks, system backups, system upgrades (for all EMS being supervised on the network). These tasks are accomplished faster by having a local team versus opening tickets against the vendors for assistance.
According to the collaboration levels to be implemented (see section 6.2), privilege access to different files/systems may be granted to tenant NOCs. The first consideration should be based on the permissions that the NaaS operator will grant to the customer MNOs to access their systems. In a similar vein, the NaaS operator NOC would require permission to access the systems of the tenant NOCs so the level of access must be conceded accordingly. These considerations should be handled by the OSS & tools management team as coordinator.
The collaboration strategy covers four areas: ticketing, fault management, performance management and billing & revenue reconciliation (further details in section 6.2). For these areas, the degree of privileges can vary from one MNO to another. If systems are interconnected usually through APIs or standardized interfaces the OSS & Tools team will oversee the level of access of tenant NOCs to access only to network data or equipment related to a specific MNO or its customers. Customer MNOs must not be capable of accessing the complete information of the network since this may cause privacy issues.
The most often used metrics to evaluate this function are:
3.1.6 Access Management
Access management is responsible for site access requests and follow up.
Activities performed by this team include:
The access management function ensures that access to the different sites in the network will be ready when needed by the field technicians or service providers. This mitigates the burden for the field management team as this function is normally associated with them if the NOC does not have this team within their structure. In the case that the field technicians from the NaaS Operator need access to a customer MNO facility, the access management function will also be in charge of coordinating with tenant NOCs the access to those sites (e.g., installing equipment on an MNO facility for interconnection).
Typically used metrics to evaluate the performance of this function are:
3.1.7 Field Dispatch
Field dispatch covers the coordination for on-site interventions that are executed on the network.
Activities performed include:
The field dispatch function is another critical function peripheral to a NOC as the team resolves all on-site interventions, including both corrective and preventive maintenance tasks. This specific function will be covered in far more detail in the Field Force Management module.
3.2 NOC Functions Selection & Customization.
This section examines the possible scenarios for the deployment of functions on the NOC organization, presenting alternatives to choose from, based on the NaaS operators scope and needs.
Below, the different options to customize the functions for each team in the NOC are examined.
3.2.1 NOC Tier 1 Setup
As stated before, the tier 1 team is the first point of contact when an issue in the network arises. However, the configuration of functions for this team can vary based on the NaaS operator requirements and constraints. The sections below, provide an overview and guidance for NaaS operators to select the option that best suits their needs.
3.2.1.1 Network Surveillance + Fault Management Scenario
The aggregation of network surveillance and fault management is one of the most common scenarios at the tier 1 level. Since network surveillance and fault management tier 1 go hand-by-hand, these two functions are usually met by one single instance which is accommodated into a NOC tier 1 level. This group of people will both perform real-time monitoring of all alarms, create trouble tickets, perform first-level analysis and diagnosis, and escalate the ticket to the corresponding fix agent if unable to resolve.
The group will also be responsible for all email and phone call communications regarding the tier 1 team, including exchanges for site conditions, active alarms, and network alarm status.
NaaS operators should select this option if a high volume of alarms/tickets is not expected, or if they wish to keep both functions tied to a single team in order for the tier 1 team to have a complete picture of both alarms and trouble tickets.
3.2.1.2 Region Segmentation Scenario
Another common setup revolves around aggregating the access management and field dispatch functions into the tier 1 team as well. This can prove effective when the NOC is monitoring a small network (or if network monitoring is broken up into different regions, each one covered by a small team of engineers).
In this scenario, the tier 1 team will also be in charge of executing field dispatches (if necessary) and making the necessary adjustments to make sure that there will be access to the site for the field technicians.
As mentioned before, this option is best suited for region-based monitoring or for small networks, as the increase in functions makes them aware of all details for their respective sites, but in turn, the overhead associated with this setup may challenge the team.
3.2.1.3 Domain Segmentation Scenario
Another common scenario is to have the NOC tier 1 team segmented into the different network domains, typically RAN, TX and CORE, especially if the alarm volume expected will be high. As such, each team monitors and creates trouble tickets for the alarms coming in from the different network elements in each domain.
For instance, the RAN tier 1 team monitoring a 4G network would receive alarms from the eNBs and the cell site routers, working closely with site-level fix agents, like field technicians covering such sites, tower companies, power companies and fiber companies. The TX tier 1 team would receive alarms from the IP aggregation and backbone routers, working with field technicians, power companies and fiber service providers. Finally, the CORE tier 1 team would receive alarms coming from the EPC network elements like the MME, SGW, PGW, etc.
This setup is more complex than the previous one, as all tier 1 teams must be in constant communication and coordination to successfully correlate alarms to incidents within the network. Some operators choose to have only two tier 1 teams: access (including all RAN and aggregation nodes) and CORE. These segmented scenarios make more sense to operators with medium-to-large site presence and can be combined with the previous region segmentation mentioned earlier for better results in larger, nation-wide networks.
3.2.1.4 Enhanced Tier 1 Scenario
Finally, one less common setup is incorporating fault management tier 2 functions to the NOC tier 1 team in addition to the previously mentioned functions. This is referred to as a tier 1.5 team, or enhanced tier 1 team.
This option may be taken for budget constraints as there would only be one team overseeing, analyzing, and processing all activities within the network, escalating complex cases directly to the vendors. This setup requires engineers with a higher level of expertise which must be taken into consideration. This can be an option for small networks with more relaxed service level agreements, as cases escalated to vendors may extend resolution times.
Table 1 below shows a summary of the scenarios that were covered in the previous sections:
|
NOC Tier 1 Setup Scenario |
Functions |
Applicability |
|||||
|
Network Surveillance |
Fault Management Tier 1 |
Access Management |
Field Dispatch |
Domain Expertise |
Fault Management Tier 2 |
||
|
Network surveillance + fault management |
✔ |
✔ |
Small networks with a high volume of alarms/tickets not expected. Retain both functions for a complete picture of network status at the tier 1 level |
||||
|
Region segmentation |
✔ |
✔ |
✔ |
✔ |
Small-to-medium network being monitored; tier 1 specializes in each region details |
||
|
Domain segmentation |
✔ |
✔ |
✔ |
Medium to large networks being monitored. Each team specializes in a specific domain requires coordination among teams |
|||
|
Enhanced tier 1 (tier 1.5) |
✔ |
✔ |
✔ |
✔ |
✔ |
✔ |
Small-to-medium networks; used in budget constraint scenarios as one single team encompasses all functions |
Table 1 — NOC Tier 1 Scenarios.
3.2.2 NOC Tier 2 Setup
As tier 2 teams are more specialized with equipment/technology, they are regularly set up within domains like RAN, TX and CORE. In addition, the following function bundles are assigned to the Tier 2 Team.
3.2.2.1 Fault + Performance Tier 2 Scenario
The most notable function aggregation scheme for tier 2 incorporates the performance management function into the tier 2 responsibilities (which as seen on section 3.1.4 comprises domain-specific expertise analysis and diagnosis, or escalations to vendor support for complex cases).
This option is adopted by NOCs in which Operators do not have network performance set as a priority. As such, Network Performance is not monitored in real-time and is only escalated to the NOC tier 2 team via end-customer reports. This setup is also considered if the operator does not have ample RF or Optimization resources available, as performance investigations are commonly referred to those groups as well.
3.2.2.2 Fault + Performance + OSS Tier 2 Scenario
On smaller NOC operations OSS & tools responsibilities are also aggregated to the NOC tier 2 team, as they are enabled to perform user/profile adjustments, take system backups, and become the point of contact for vendor engagement.
Table 2 summarizes the scenarios covered in the previous sections for tier 2:
|
NOC Tier 2 Setup Scenario |
Functions |
Applicability |
|||
|
Fault Management Tier 2 |
Performance Management |
OSS & Tools Management |
Domain Expertise |
||
|
Fault + performance |
✔ |
✔ |
✔ |
Performance not set as a driver for the operator, or if operator is missing Optimization resources |
|
|
Fault + performance + OSS |
✔ |
✔ |
✔ |
✔ |
Budget constraint Operators as most of the cases will be escalated to vendor for support |
Table 2 — NOC Tier 2 Scenarios
3.2.3 NOC Leadership
NOC leadership duties include NOC planning, controlling, steering, and reporting all aspects of NOC activities; management of NOC organization and NOC staffing; delegation and empowerment of NOC managers and team members. Within those duties, the following main activities are performed:
Figure 4 shows the most common structure for NOC Leadership, which will be explained in detail in the following paragraphs:
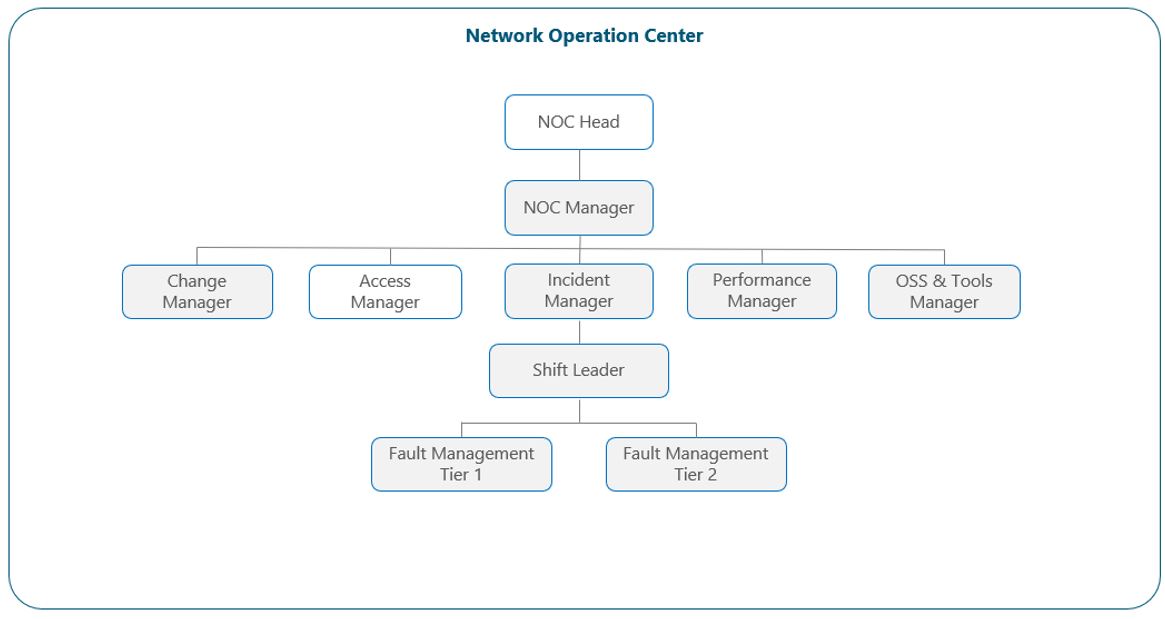
Figure 4 — Network Operations Leadership View
Each NOC group is usually supervised by a manager who delivers guidance to the entire team and serves as the point of contact (POC) for all those team requirements or escalations. Depending on the setup that has been chosen, leaders for network surveillance, fault management tier 1, fault management tier 2, performance management, OSS & tools management, access management, incident management and field dispatch may exist; or a manager for the aggregated teams may be in place (e.g., NOC tier 1 manager, NOC tier 2 manager). The entire team is supervised by a NOC head, who acts as the ultimate responsible for the NOC operations.
Another common practice in medium-to-large NOC organizations is to have a manager per domain, specifically at the tier 2 level. This decision is based on the expertise that is needed for such teams and to have a direct escalation path available for specific-domain scenarios that may be present on the network, thus aiding for faster resolutions since the leader can provide directions for the team and readjusting priorities as needed.
Since regardless of the grouping decisions the tier 1 team is always one of the biggest groups, team leaders are regularly set as part of the structure (having at least one team leader per shift). These people are trained engineers whose expertise and process knowledge, supported by leadership empowerment, enables them to make controlled operative decisions during their shift in absence of the teams manager.
Further guidance on the configuration of the NOC leadership team is provided in section 6.4.
4. NOC Processes
This section presents the core processes followed by the NOC including E2E process flows, key elements, roles and responsibilities and the most common metrics used to measure each process success. The section also presents guidance for the operators NOC processes customization.
4.1 NOC Processes Analysis
The following subsections analyze each process executed at the NOC, including rationale, common KPIs and roles associated with each process.
4.1.1 Event Management
An event is regarded as a change of state that has significance for the management of a resource or service. It can also mean an alert or notification created by any service, resource or monitoring tool.
Events typically require operations staff to take actions, and often lead to incidents being logged. The event is only recognized as an incident at the end of the event management process.
Figure 5 presents the high-level E2E process flow for event management which is also provided as a template for customization by NaaS Operators. The green dots on the left indicate input triggers to the process and the red dots are endpoints of the process.
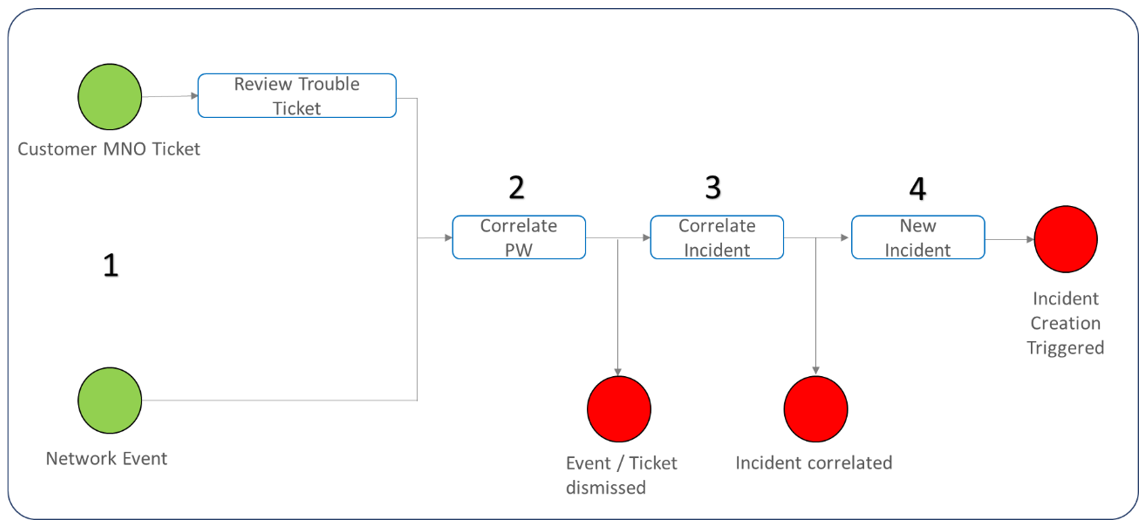
Figure 5 — Event management high-level flowchart
Below, the process is described in detail:
Event Management is typically measured by two KPIs:
4.1.2 Incident Management
To understand the incident management process, the following definitions are required:
The high level, end to end process flow for Incident Management is presented in Figure 6 below and provided as a template for NaaS operator customization.
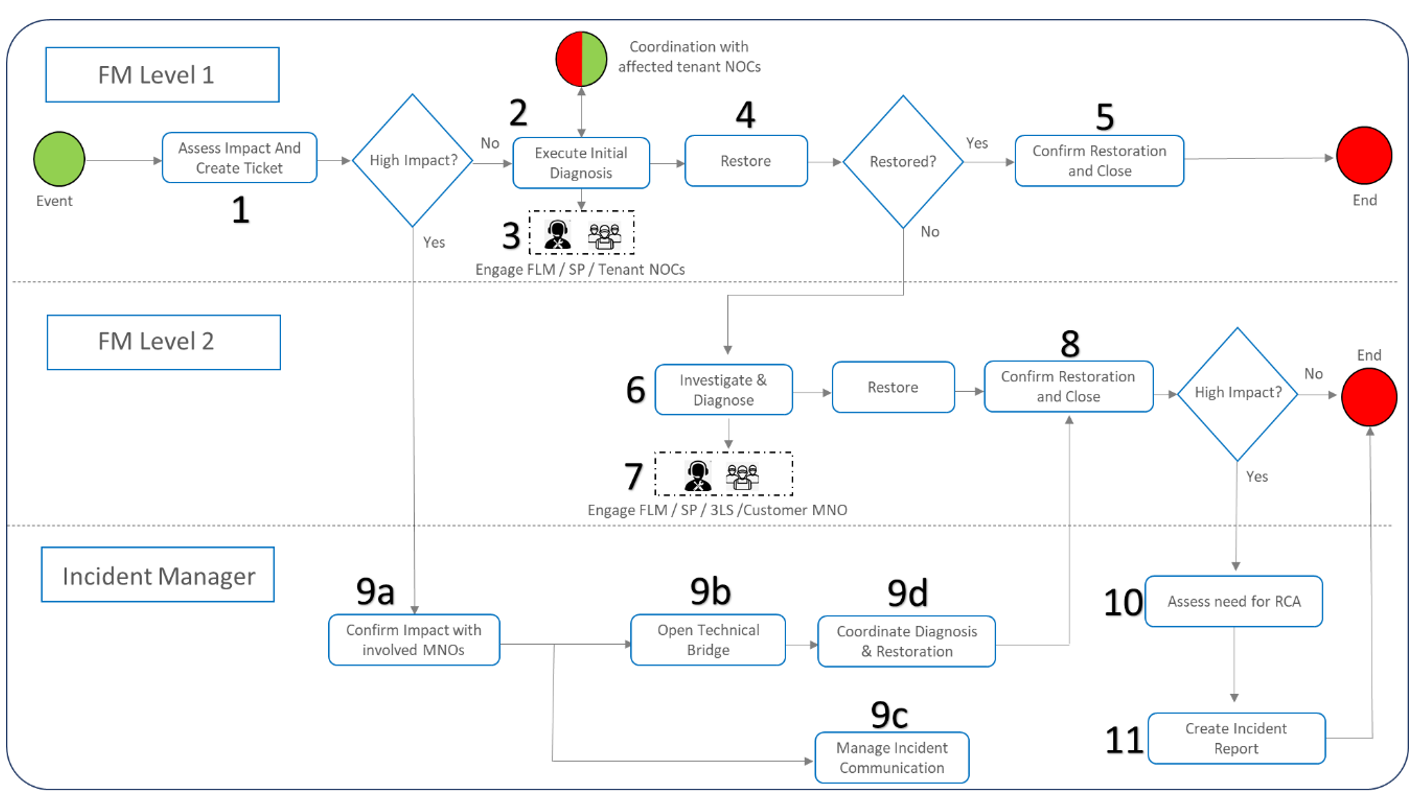
Figure 6 — Incident management high-level flowchart.
The high-level E2E process flow for the incident management process is divided into 3 lanes, to address the role of each of the participants in the process. The upper portion shows process steps for the FM tier 1 engineers. The middle lane shows the activities performed by the FM tier 2 engineer. The bottom lane indicates the process steps executed by the incident manager. It is precise to remark that depending on the implementation model, the tier 2 NOC may belong to the customer MNO. The green dot on the left is an input trigger to the process. The red dots are endpoints of the process. Below a detailed description of this process is provided:
The most common KPIs utilized for incident management are the following:
4.1.3 Problem Management
To understand the Incident Management process, the following definitions are required:
Figure 7 introduces the high-level, E2E process flow for problem management which is also provided as a template for customization by the NaaS operator.
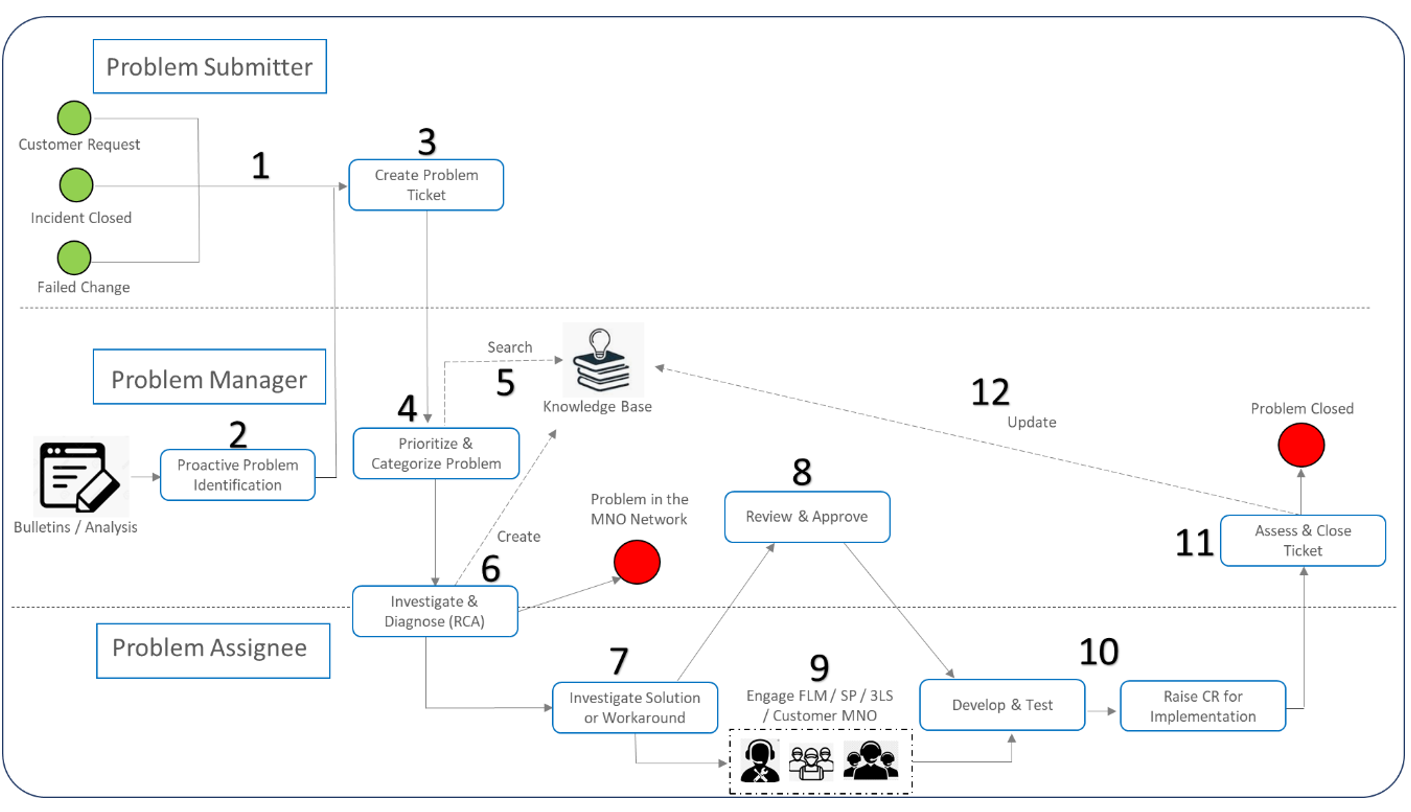
Figure 7 — Problem management high-level flowchart
The high-level E2E process flow for the problem management process is divided into 3 lanes to highlight the roles involved and activities to be taken by each role. The upper lane has process steps for the problem submitter. The middle lane shows the activities performed by the problem manager. The bottom lane shows the process steps executed by the problem assignee. The green dots at the beginning of the problem submitter lane show input triggers to the process. The red dot is the endpoint of the process. A detailed description of this process is provided below:
The most common KPIs used to measure problem management are:
4.1.4 Change Management
A network change refers to the addition, modification, or removal of any network infrastructure network element. This includes changes to hardware, software, configuration, and database. First, some concepts that are important to the change management process are provided:
The high-level, E2E process flow for change management is presented in Figure 8. This process flow is provided as a template for customization.
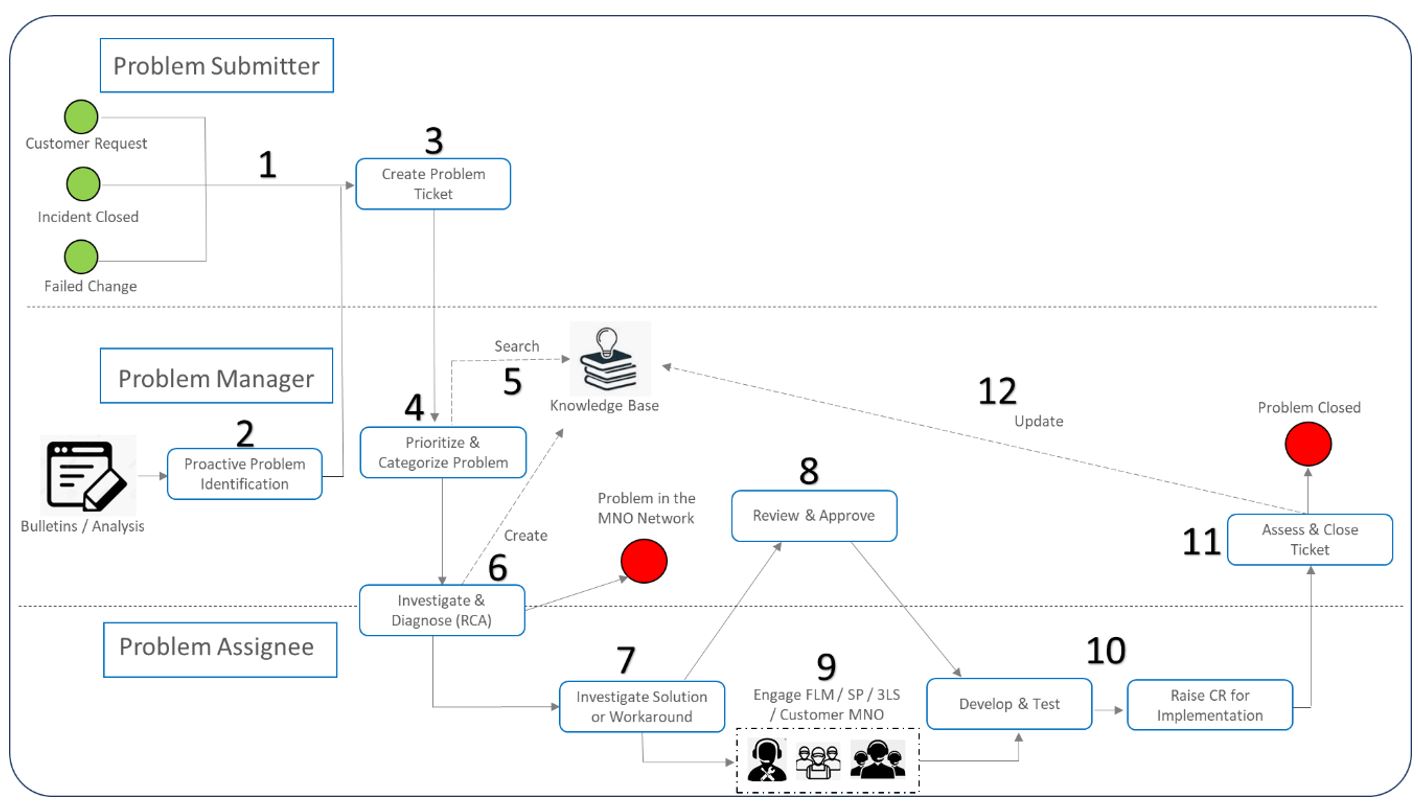
Figure 8 — Change management high-level flowchart
The blue boxes on the left are the primary roles of the process. Horizontal lanes, associate process steps with the respective roles. The green dots on the left are the input trigger to the process, and the red dots are the endpoints of the process. In the following paragraphs, a detailed description of the process is provided:
Once the updates in documentation to the required system are performed (asset and configuration database), the process moves to the last step, which is preparing the implementation report and closing the change ticket.
Typical KPIs used to measure the change management process are:
4.2 NOC Process Selection & Configuration
Now that the NOC processes have been analyzed the NaaS Operator must select the processes to be implemented based on the NOC scope and NaaS operator capabilities or requirements.
Event management, incident management and change management are mandatory processes for a NOC operation. Still, there are three process adjustments that may be considered by the NaaS operator:
5. Systems & Tools Overview
This section provides an overview of the systems and the most common tools used to support the network operation, and aspects to consider for the NaaS operator evaluation and selection of tools to be incorporated into their NOC.
5.1 Tools High-Level View
There are several tools in place for a NOC to achieve its objectives. The most widely used are the service desk management tool, a network fault management system, a geographic information system, network performance management system and network configuration management systems. These will be reviewed in the following sections.
5.1.1 Service Desk Management Tool
This tool is used for the documentation of all incidents, problems and changes that are being worked on the network at any given time. It can be considered one of the main tools used by the NOC, as it enables all the team to have a proper mechanism to document all activities surrounding each incident, problem or change ticket.
A proper tool for documentation aids the team as they can know exactly what the status of any ticket is, what are the next items to be solved and what needs to be followed-up. It also enables reporting, which serves as the basis for governance activities: revision of the NOC performance, KPIs, and SLAs.
A full service desk management (SDM) tool is an immensely powerful tool that incorporates modules for incident management (incident tickets), problem management (problem tickets) and change management (change tickets). It also includes a Knowledge Base module (KB Articles) that serves as a repository for all the KB information used by all NOC teams, updated with key past experiences and lessons learned for future reference and improvements, as previously discussed on the problem management process section.
Another alternative to consider is to have a ticketing tool instead of an SDM tool if focus will be set on fault restoral and less on problem or change management. This will be further discussed in section 5.2.
When choosing the appropriate tool, one point to consider is the scheme of collaboration between the NaaS NOC with the tenant NOCs. An automated mode will require the SDM/ticketing tool to communicate to the tenant NOCs. In this scenario, the tool must support a standardized interface towards the tenant NOC for easier and automatic TT sharing.
Examples of commercial and free/open-source tools are provided in Table 3.
|
Free/Open Source Tools |
|
|
BMC Remedy ITSM |
OTRS Community ITSM |
|
ServiceNow ITSM |
CNTS C-Desk |
|
Cockpit ITSM |
Freshwork Freshservice |
Table 3 — Commercial vs Free/Open Source Service Desk Management Tools
5.1.2 Network Fault Management System
A NOC needs a visible medium to monitor alarms which is accomplished by a network fault management system or network monitoring system as described in the Network Monitoring Architecture module. This tool, along with the service desk management tool covered earlier, are the heart of any NOC organization. This tool enables the network surveillance function, as alarms are monitored and observed by the NOC technicians, and therefore ticketed for resolution following event and incident management processes.
This tool provides the NOC tier 1 team basic alarm functionality to acknowledge alarms (i.e., mark an alarm as observed and being analyzed), journal alarms (i.e., introduce text to the alarm indicating trouble ticket opened, or change associated to alarm, or other information deemed necessary) and clear alarms (i.e., set an alarm as already worked and dismissible from further work).
There are two common options commonly available for NOCs regarding fault management tools: one of them is having an umbrella network management system. An umbrella system helps the NOC organization by having all alarms, regardless of the network element vendor, available for monitoring on a single tool. This type of tools can interact with the service desk management tool to create tickets directly from the alarming tool or to append alarms directly to an existing incident ticket.
The other option is to have the tier 1 teams monitoring the different EMSes directly. These EMS tools have all the basic functionalities needed for network surveillance (i.e., acknowledge alarms, journal alarms, clear alarms).
Like the previous section, the tools from network fault management should be capable of importing and exporting the alarms to synchronize the current faults of the networks (NaaS and MNOs). If customer MNOs and NaaS agreed to automate the process, the fault alarms should be shared automatically between systems by a directly connected interface. Its important to note that not all the fault alarms should be shared, but only those relevant to customer MNO service.
Examples of umbrella NMSes and EMSes are provided in Table 4.
|
EMS |
|
|
IBM Tivoli Netcool/OMNIbus |
Huawei U2000 |
|
Teoco Helix Fault Management |
Nokia NetAct |
|
Atrinet NetACE |
Ericsson OSS-RC |
|
Samsung LSM-R |
Table 4 — Umbrella NMS vs EMS Tools
5.1.3 Geographic Information System (GIS)
The GIS tool serves as a one-stop-shop for all items needed for troubleshooting for a particular site. A GIS tool is a support tool for NOC technicians to have all information ready and available in a visible, fast way.
This tool is used to obtain all relevant information about a particular site, such as:
Sharing information between the NaaS operator NOC and tenant NOCs is crucial to solve problems quickly and effectively. If the agreements between NaaS operator and MNOs establish the need to have full access to GIS data, the GIS tool must support a standardized interface towards the tenant NOC for remote collaborative work. Besides, the NaaS Operator should grant access permission to certain GIS information (e.g., Tx information, coordinates, and network configurations relevant to a certain MNO) of the project so the tenant NOCs would only have access to the information important to them.
Examples of commercial and free/open-source tools are provided in Table 5.
Table 5 — Commercial vs. Free/Open Source GIS Tools
5.1.4 Network Performance Management System
This tool aids the NOC organization to monitor the performance of the network in a more accessible manner. This is strategic for teams focusing on network performance indicators or for teams investigating network degradations before they are reported by end-users. Network performance can be categorized into RAN/CORE KPIs and IP/TX KPIs.
Performance Management tools enable the teams to analyze trends on several pre-defined KPIs, and granularity is often offered from months down to hours perspective. Another useful feature is to enable teams to create their own KPIs based on the available metrics offered by each element in the network, or put in another way, to customize the indicators for a far more operator-coherent experience. Further details are provided in the Network Monitoring Architecture module.
Analogous to section 5.1.2, if the agreements with customer MNOs stipulates a certain degree of collaboration level, the connection through a direct standardized interface from NaaS operator NOC to tenant NOCs will be mandatory for the tool to share performance KPIs (the interface should work on both ways so involved parties are aware of the performance of one another). Its important to note that not all the KPIs should be shared, but only those relevant to a certain MNO.
Performance Management tools are usually classified based on the domain in RAN/Core and IP/Transport. Table 6 provides examples of commercial and free/open-source tools by domain.
|
Commercial Tools |
Free/Open Source Tools |
|
Nokia Performance Manager |
Grafana |
|
Ericsson Network Manager |
Kibana |
|
Teoco Performance Management |
Prometheus |
|
Netscout nGenius |
|
|
BWTech Netchart |
|
|
IP/TX Network Performance |
|
|
Commercial Tools |
Free/Open Source Tools |
|
Solarwinds Network Performance Monitor |
Nagios |
|
Paessler PRTG |
Zabbix |
|
Progress WhatsUp Gold |
LibreNMS |
|
CACTI |
|
Table 6 — Commercial vs Free/Open Source Network Performance Management Tools
5.1.5 Network Configuration Management System
This system helps the NOC to oversee the configurations of the network equipment in a centralized fashion. This is helpful for teams responsible for change management or for teams in charge of troubleshooting.
Configuration management tools have three main advantages: to help keep the network configuration consistent, to ease the problem solving, and to allow the automation of the network. These tools help to keep the consistency of the network since any difference in the configuration for similar equipment can be spotted and corrected more easily. It also aids the change management teams to monitor the changes on the equipment in near real-time. Regarding the problem-solving process, having the configuration files centralized and updated may reduce the time to provide a solution. Lastly, these tools allow a network to be partially or fully automated since having a centralized tool for configuration is the first step towards network orchestration and automation.
As stated in previous sections, the collaboration with tenant NOCs is key for effective work. Similarly, if agreed by the Naas and customer NOCs, it can be necessary the direct connection between the configuration management systems (e.g., through APIs, SNMP Traps, or standardized interfaces). It is important to note that not all the configurations should be shared, but only those relevant to a certain MNO.
Finally, it is important to note that the NMS tools from different vendors can act as network configuration management tools. The obvious limitation is that an NMS will only work for the equipment from that vendor (some vendors would require more than one NMS tool). If the NaaS Operator Network is built of equipment from several vendors, the number of NMS tools will increase accordingly.
Table 7 provides examples of commercial and free/open-source tools.
|
Commercial Tools |
Free/Open Source Tools |
|
Atrinet NetAce |
ConfiBack |
|
TrueSight Automation for Networks |
rConfig |
|
Teoco SmartCM |
Westermo WeConfig |
|
Comarch Mobile Network Configuration Management |
|
|
ManageEngine Network Configuration Management (NCM) |
|
|
SolarWinds Network Configuration Manager |
Table 7 — Commercial vs Free/Open Source Network Configuration Management Tools
5.2 Systems Selection
In the previous section several tools that are part of a NOC ecosystem were introduced. Now aspects to consider for tool evaluation and selection will be presented. First, critical operational tools will be discussed, followed by optional support tools.
5.2.1 Critical Operational Tools
There are a couple of tools that are critical and must be part of the NOC solution: the network fault management tool, the service desk management tool and configuration management tool. The first one is the key component of network surveillance and event management; the second one is vital for incident management and fault management teams; and the third is vital for change management and fault management teams. Below the recommendations and considerations to be taken into account by the NaaS operators for the selection of these tools are provided:
5.2.2 Support Tools
In the following paragraphs, the GIS and the network performance tools will be discussed, which are support tools that are optional depending on the needs of the NaaS operator.
6. NOC Implementation
This section presents a discussion of the different scenarios available to the NaaS operator regarding NOC implementation including staffing model, service levels, team dimensioning and facility sizing.
6.1 Staffing Model Assessment
There are two main models available for NOC staffing that can be considered by the NaaS operator: insourcing (i.e., building the NOC with internal resources as part of the NaaS organization) and outsourcing (i.e., reaching out to a third party to take control of operations), both of which will be covered in more detail in the next paragraphs.
An optional third alternative will also be presented, in which the NaaS operator may choose to outsource some tasks while retaining the majority of their operations. This option will also be covered after reviewing the first couple of models.
Regardless of the model to be chosen, there are several key aspects that the NaaS operator will have to bear in mind for the NOC implementation:
All these aspects have been outlined in this document in the previous sections, and the operator will have to define the implementation strategy that best fits their organization taking all these factors into consideration.
A closer examination of the implementation alternatives is presented below:
6.1.1 Staffing Model Selection Guidelines
The insourced model offers full control of the operations to the NaaS Operator, allowing for changes in process/functions to be completed according to the business needs as soon as possible. Compared to the costs associated with the outsourcing model, the insourced model offers a way to drive down costs as needed.
However, insourcing may render difficulties for the NaaS operator as all hiring and training must be performed by them. Because of this, the insourced model is recommended for mature organizations with good human resources practices in place and confidence in the tools/processes to be implemented or for NaaS operators with small networks and tight budget constraints.
The outsourced model is often a costly option, still it offers several benefits as the NaaS operator is liberated from all the HR burden, including training and retaining highly skilled professionals, as well as tool selection and implementation. This is often one of the most difficult scenarios, especially at the beginning of operations, as NOC engineers have to learn at first a networks architecture and technology, the entire range of processes built around the NOC, and tool utilization.
A NaaS operator should select the outsourced model if the costs associated with outsourcing outweigh the costs associated to having an operation that is not working properly or that is not mature enough.
The mixed schema is suitable for NaaS operators that have maturity in certain aspects of the operation but are struggling in other areas, or for operator facing a multi-vendor distributed network experiencing difficulties to hire personnel with the right skills and knowledge for such challenge, as the third party can assist the operator fulfilling such gaps while the company gains such knowledge and skills.
6.2 NaaS-MNO Interconnection & Collaboration Strategy
The operational model of the NaaS operator will always rely on a close relationship with other MNOs, mainly as customers. Under this assumption, the NOC needs to be in constant communication with NOCs from other MNOs (tenant NOCs). The collaboration strategy will focus on areas on which is critical to maintain a level of communication. There are basically four communication areas that need to be addressed by this strategy:
Figure 9 shows the possible NOC interaction areas (A-D, as previously stated) for the collaboration strategy:
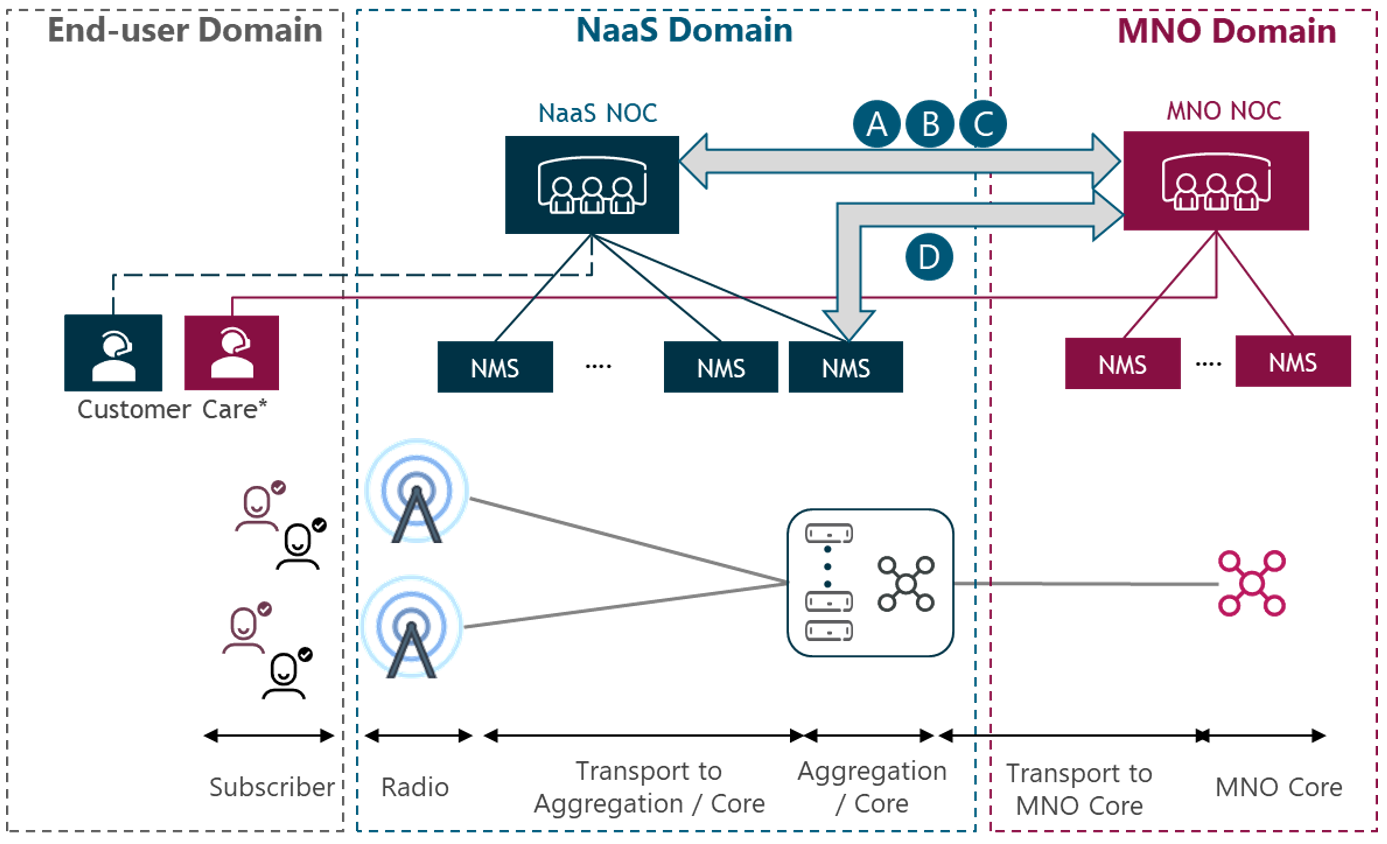
Figure 9 — NaaS-MNO inter-domain collaboration diagram
The collaborative strategy for the NaaS operator and their customer MNOs begins with the cooperation on the event management process. In this process, any alert or notification raised by any service, resource or monitoring tool is reported in the form of TTs. These TTs are analyzed and solved or escalated by tier 1 NOC in later steps. Ticketing is the most crucial activity since it represents the main input that drives all the NOC activities.
The next task in the NOC overall process is the fault management on any anomaly reported by event management. In this phase, the communication is vital: the faster, the better. An earlier and clearer exchange of information between involved parties would lead to a quicker resolution. The tier 2 and tier 3 support following the fault management stage can be on the NaaS or MNO side (depending on the NOC implementation model).
The other two processes for which a lower degree of integration of systems is required are performance management and billing & revenue reconciliation. The first refers to the constant monitoring of the network looking for poor performance of the network or opportunity areas where to increase the performance. The integration of performance systems can lead to a better understanding of the network and cooperative measures or changes can be implemented more effectively.
The last process is the billing and revenue reconciliation. This stage is key towards a successful business partnership between the NaaS operator and their customer MNOs. The purpose of this task is to reach agreements on the periodic billing or revenue amounts based on the associated costs and profits of the network operation. Again, communication is the key to avoid misunderstandings and to efficient the overall process.
There are two generic modes for all the integration of the communication conduits mentioned above: the manual and the automated. The first is characterized by a minimum or non-existent integration of the involved systems and relying on basic and slow human one-to-one or one-to-many communication. The automated mode targets for almost full integration of the systems. The intercommunication of these systems is based on automatic request and replies which lead to a near-real-time interaction.
In subsequent sections, the method of systems integration and its implications are explained.
6.2.1 Ticketing
As previously stated, ticketing is one of the pillars for NOC activities, so it is a mandatory item in the collaboration strategy. The purpose of this system integration is the fast and clear exchange of information for any irregularity in the network or the service. For any NaaS operator, this is mandatory for a healthy relationship with their customer MNOs.
There are several advantages when implementing an efficient ticketing process: reduction in the response times when an abnormality in the services/network occurs and decreasing of the overhead for the MNOs when opening a ticket. The disadvantage would be that the integration of systems can be hard to achieve when the already implemented tools do not allow this option.
Manual Mode
This scheme avoids the system integration with ticketing from tenant NOCs. The tenant NOCs may have independent tools from NaaS operator, and no special feature or interface is needed. The collaboration is via phone calls or formal emails. When an email or phone call takes place to open a TT, the NaaS Operator NOC personnel must manually insert the details into their SDM/ticketing system. This method could lead to errors in capturing the details of the problem besides the long times for reporting.
Automated Mode
The SDM/ticketing systems are interconnected so the TT can be raised directly by the customer MNO and the NaaS operator NOC can initiate the process towards the solution. After the resolution of the problem, the NOC can close the created ticket and the tenant NOCs are informed of the outcome almost instantly. An example of this system is a web- or cloud-based ticketing.
6.2.2 Fault Management
Fault management is the second pillar of NOC functionality and mandatory in the collaborative strategy. The system integration objective is to reduce the necessary time for problem solving and escalation time towards the compliance of pre-agreed SLAs.
The advantages and disadvantages are quite like the ones of ticketing due to the closeness of these two processes. It reduces the time for problem-solving since it offers alarms and diagnostic elements almost instantaneously. Furthermore, it enables the operator to have a shared source of truth and optimizes the overall process by eliminating points of human failure. On the other side, although the integration of FM systems is more feasible (compared to the ticketing), it is not always possible due to lack of compatible interfaces. It is required that the interfaces for interconnection are compatible from system to system.
Manual Mode
In the manual mode, the fault management systems are not interconnected and the exchange of information such as alarms of network/service is done by sharing a compendium of alarms files if the tool allows it. These files can be shared by email or any other formal channel.
Automated Mode
When the systems are interconnected and the alarms & notifications are delivered automatically between the fault management tools, the information of the alarm is not modified, and the integrity is preserved. The update of the notification is in real-time and the analysis of the issue is done with no delays. The fault management tool uses a request/response paradigm to communicate through standardized interfaces (e.g., SNMP traps, API exposure, NETCONF protocol based). Examples of these are umbrella tools and the interconnection of EMS/OSS systems.
6.2.3 Performance Monitoring
Performance Monitoring has less criticality since it is an extended function of the NOC and can be considered as optional. Here, the purpose of the integration is to draw more attention on the performance KPIs so its easier to find areas of opportunity for enhancements of the network.
The advantages are that more people can analyze the performance KPIs and it is more likely to find a root problem or any improvement in the usage of the network. The disadvantage would be that the integration is more challenging to achieve than the previous systems since, in this case, the access should permit MNOs to only access their own KPIs. If access is not properly controlled, a privacy issue may be raised. In this case, the access management is more challenging since the permissions have more precise delimitations.
Manual Mode
When implementing a manual mode, the exposure of the KPIs may be done through periodic reports or presentations. Since it is not a mandatory requirement, these reports may not always be shared and should be requested via formal email or phone call. This process would require a certain degree of organization between the NaaS operator and the involved MNO. It also needs more human effort into generating these reports/presentations according to the total number of MNOs.
Automated Mode
In this method, the systems integration is achieved by connecting the system tools to share the appropriate KPIs to the corresponding MNOs. One MNO should only have permission to look into the KPIs that are relevant to it. The coordination between tools should be more precise, but the results are the monitoring of the network performance in real-time.
6.2.4 Billing and Revenue Reconciliation
On the business side, the collaboration strategy contemplates the reconciliation of billing and, when it applies, revenue. The purpose of the integration of this system is to assure the data integrity and provide clarity of the billing and revenue. This must be considered mandatory to the collaborative strategy since the heart of the relationship between the NaaS operator and their customer MNO is business-based.
The pros of having these systems integrated are that the data used for billing and revenue clarifications is unmodified as a unified source of truth. Moreover, continuous monitoring can lead to better business estimations without the need of waiting for the periodic reports. The con is that data must be selected before shared with MNOs to avoid any information leak to other MNOs. This would also involve the overseeing of access to the systems involved.
Manual Mode
In this mode, the billing and revenue reconciliation is done by periodic meetings with business areas from a specific MNO. The MNO and the NaaS operator need to have implemented independent tools to have a formal discussion if the processed billing data differ. In this scheme, the human effort is increased by the number of MNO, since a customized report and an isolated meeting should be carried out per MNO.
Automated Mode
The automated mode considers the integration of the billing systems at BSS level. The information is pre-processed only to select the pertinent information to be shared per MNO. A formal meeting is always a good practice when billing data differs. Here, the BSS has more standardized interfaces towards other BSS, so the integrations are easier.
6.2.5 Examples
The level of collaboration between the NaaS operator NOC and the tenant NOCs determines the required capabilities of the tools. In the next subsections, two examples are presented: firstly, one to show a scenario where every collaboration channel is manual and secondly, one with the most typical case for a NaaS Operator.
6.2.5.1 Rigid Organizational Model
In this type of organization, all the processes are done manually. This means that ticketing, fault & performance management, as well as billing and reconciliation are executed without any system integration. The communication channels are traditional (e.g., phone calls, email).
This organizational model is recommended as a starting point for operators who lack technical skills to integrate tools through standardized interfaces or when the operator has limited resources to implement the tools. It also helps reducing times for the NaaS operator NOC to begin to operate.
The main points of this model are contained in Table 8.
|
Level of system integration |
None |
|
Ticketing coordination level |
Phone call |
|
Fault management coordination level |
|
|
Performance management coordination level |
Only by email or formal request |
|
Billing and revenue reconciliation coordination level |
Call Data Registries (CDRs) provided to the customer MNOs |
Table 8 — Collaboration level for rigid organizational model.
This model carries the least effort in terms of integration, but it also requires more human effort.
6.2.5.2 Typical Organizational Model
In the typical model, some tasks are partially automated, and others are kept manually since the effort to integrate the systems overcome the advantages.
This organizational model is recommended as the NaaS operator NOC matures if the starting point was the rigid organizational model. The level of collaboration between the areas should always consider the effort of implementation versus the advantages that it implies when deciding. This scheme is also recommended to operators who have the necessary budget/human resources or technical skills to deploy such integration.
The main points of the typical model are as follows:
|
Level of system integration |
Most crucial operational activities (ticketing and fault management) and the business one (Billing/revenue reconciliation) |
|
Ticketing coordination level |
Web-/cloud-based system from NaaS operator |
|
Fault management coordination level |
Standardized interface from NaaS operator and vice-versa. |
|
Performance management coordination level |
Periodic reports |
|
Billing and revenue reconciliation coordination level |
Connection at BSS level |
Table 9 — Collaboration level for typical organizational model.
The web-based ticketing is an efficient way of enabling the NaaS operator to avoid the human point of error when issuing a TT; besides, it allows the NaaS operator for easy management of the TT. The FM is considered key to a combined work, so the systems are fully interconnected, and this interconnection makes the problem solving smoother. Since the performance management is optional, a standard periodic reporting is enough. Finally, the decision of billing/revenue reconciliation integration allows the NaaS operator to have a better relationship with their customer MNOs.
6.3 Service levels Definition
Service levels specify the way that an incident is treated and the expected times for response and restoration based on the severity of the incident. Therefore, the first thing that needs to be defined by the NaaS operator is a criticality matrix which specifies the classification of incidents into categories or severities.
There are typically four severities deployed in most NOC organizations: critical, major, medium and minor. The NaaS operator must decide which scenarios fit each category, for which an initial recommendation is provided below:
● MAJOR
● MEDIUM
● MINOR
After the criticality matrix is set, the NaaS operator must set two variables for each category:
The first variable is strictly NOC dependent, and is usually expressed in minutes (X minutes from alarm to ticket creation). The second variable needs consideration of several factors, including the agreed contractual SLAs with other parties (power companies, fiber/copper companies, tower companies, field maintenance) and their escalation paths. For instance, an operator might set the following service levels shown in Table 10:
|
SLA |
Response Time |
NOC Time |
NaaS Operator Restoration Time |
Driver |
|
|
Critical |
8 hours |
15 minutes |
30 minutes |
7 hours 15 minutes |
Ticket Creation: 15 minutes | Troubleshooting: 30 minutes | Restoration Tasks: 7 hours 15 minutes |
|
Major |
12 hours |
30 minutes |
30 minutes |
11 hours |
Ticket Creation: 30 minutes | Troubleshooting: 30 minutes | Restoration Tasks: 11 hours |
|
Medium |
24 hours |
60 minutes |
60 minutes |
22 hours |
Ticket Creation: 60 minutes | Troubleshooting: 60 minutes | Restoration Tasks: 22 hours |
|
Minor |
48 hours |
2 hours |
2 hours |
44 hours |
Ticket Creation: 2 hours | Troubleshooting: 2 hours | Restoration Tasks: 44 hours |
Table 10 — Service level setting example
In addition to response time and restoration time, there is another vital service level agreement that needs to be set in place, which is the network availability. Network availability targets are established throughout the high-level network architecture stream; however, as part of the NOC implementation, the NaaS operator needs to set the expectations in line with the relative maturity of the business and the network.
During NOC implementation, the NaaS operator must assess if the target availability can be reached, considering the factors below:
6.4 Team Design & Dimensioning
Once that the staffing model and the service levels have been defined, the NaaS operator must design and dimension the NOC organization. The following subsections address the NOC organization design and dimensioning, respectively.
6.4.1 NOC Organization Design
Based on section 3.2, the NaaS operator can select a configuration for the NOC organization. Following recommendations on section 3.2, three typical configurations for a NOC organization can be identified:
● CONFIG 1
✔ Tier 1 performs network surveillance + fault management
✔ There are allocated resources for both performance management and access management + field dispatch
✔ Tier 2 is separated into domains (i.e., RAN, TX, and core)
✔ There is a focused resource for OSS & tools
✔ There is one team leader per shift
✔ On the management side, there is one leadership position for tier 1, one for TX, one for core, both a problem and a change manager, an incident manager per shift and a general NOC manager
● CONFIG 2
✔ Tier 1 performs network surveillance + fault management + access management + field dispatch
✔ Tier 2 performs fault management tier 2 activities across the board for all domains, plus performance management
✔ There is a focused resource for OSS & tools
✔ There is one team leader per shift
✔ On the management side, there is one leadership position for tier 1, one for tier 2, an incident manager per shift and a general NOC manager
● CONFIG 3
✔ Tier 1 performs network surveillance + fault management + access management + field dispatch + some tier 2 activities (i.e., enhanced tier 1)
✔ Tier 2 performs fault management tier 2 activities across the board for all domains, plus performance management plus OSS & tools activities
✔ There is one team leader per shift
✔ On the management side, there is an incident manager per shift and a general NOC manager
The NaaS operator can choose one of the above configurations or define a customized configuration based on their own organizational requirements and constraints. If thats the case, guidance in section 3.2 can be applied with such a purpose.
6.4.2 NOC Organization Dimensioning
To establish an organizational structure, several factors need to be taken into consideration:
This information will aid the NaaS operator to estimate the dimensioning of the NOC team. For this purpose, the NOC dimensioning tool displayed in Figure 10 is provided.
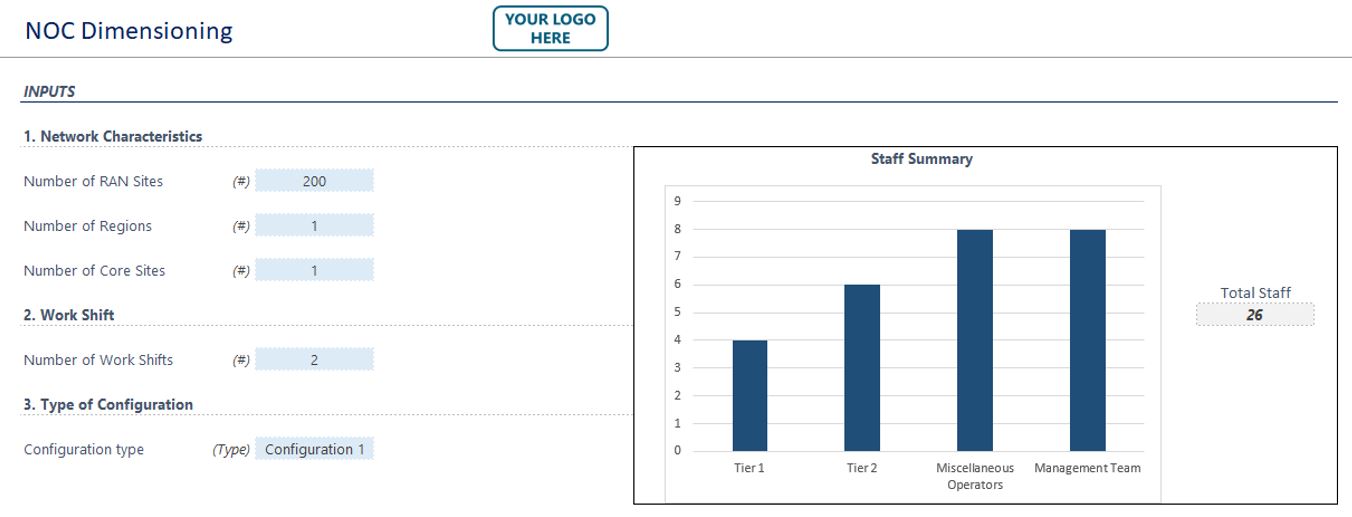
Figure 10 — Playbook NOC dimensioning tool
Each of the inputs above must be inserted in the corresponding field. The first three fields (RAN sites, regions, and core sites) are open, as shown in Figure 11:
Figure 11 — Open fields in the playbook NOC dimensioning tool
The remaining two inputs (work shifts and configuration type) have combo boxes enabled to choose from the available options, as shown in Figure 12.
Figure 12 — Combo boxes in the Playbook NOC dimensioning tool.
Once all the fields have been completed, the tool will show a summary at the top showing the headcount of NOC staff to be considered, as shown in Figure 13:
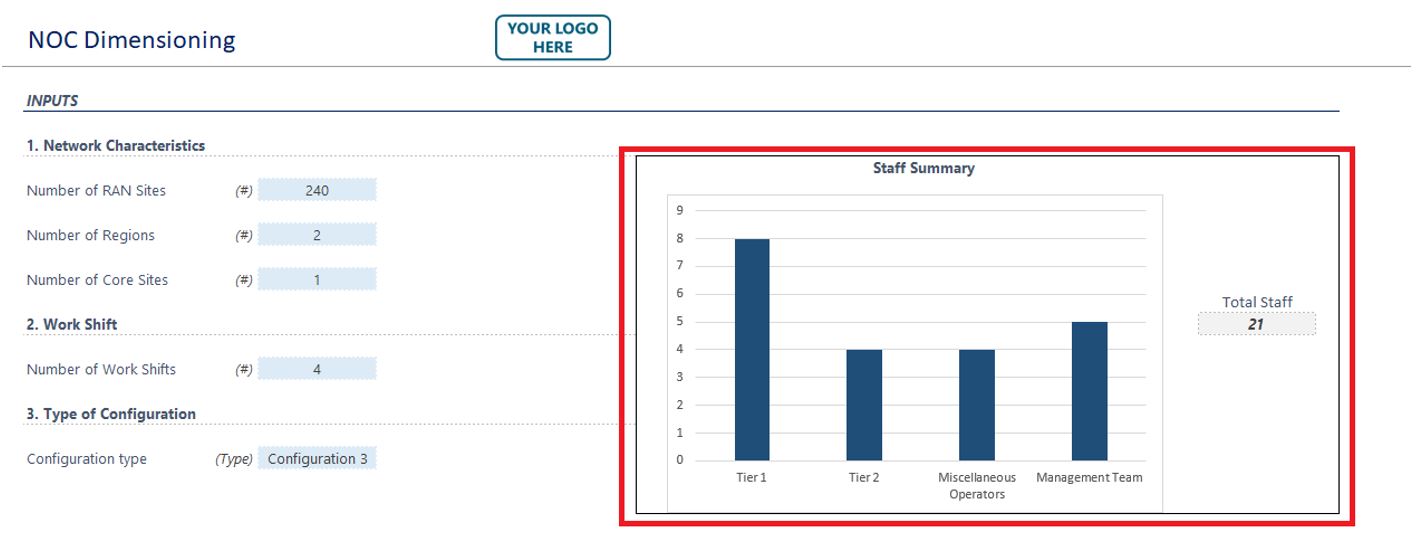
Figure 13 — Staff summary
Then a complete list of all the resources will be presented, starting with the tier 1 and tier 2 teams as shown in Figure 14:
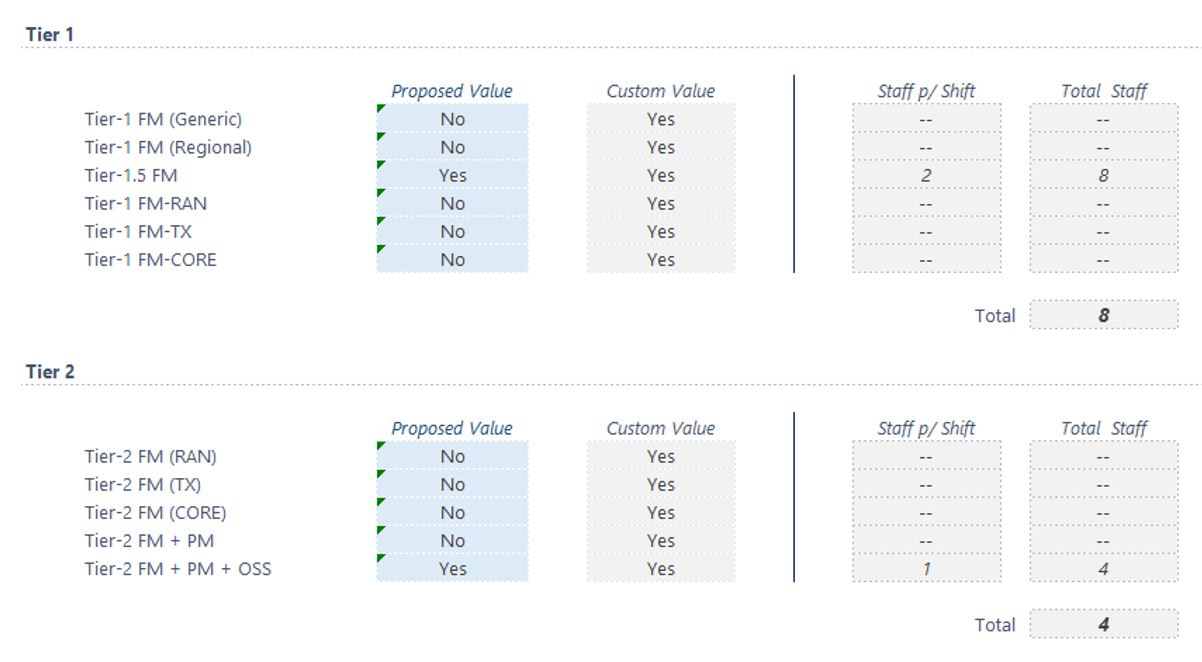
Figure 14 — Tier 1 and tier 2 resources
This is followed by the rest of the operators and the management team calculation, as shown in Figure 15:
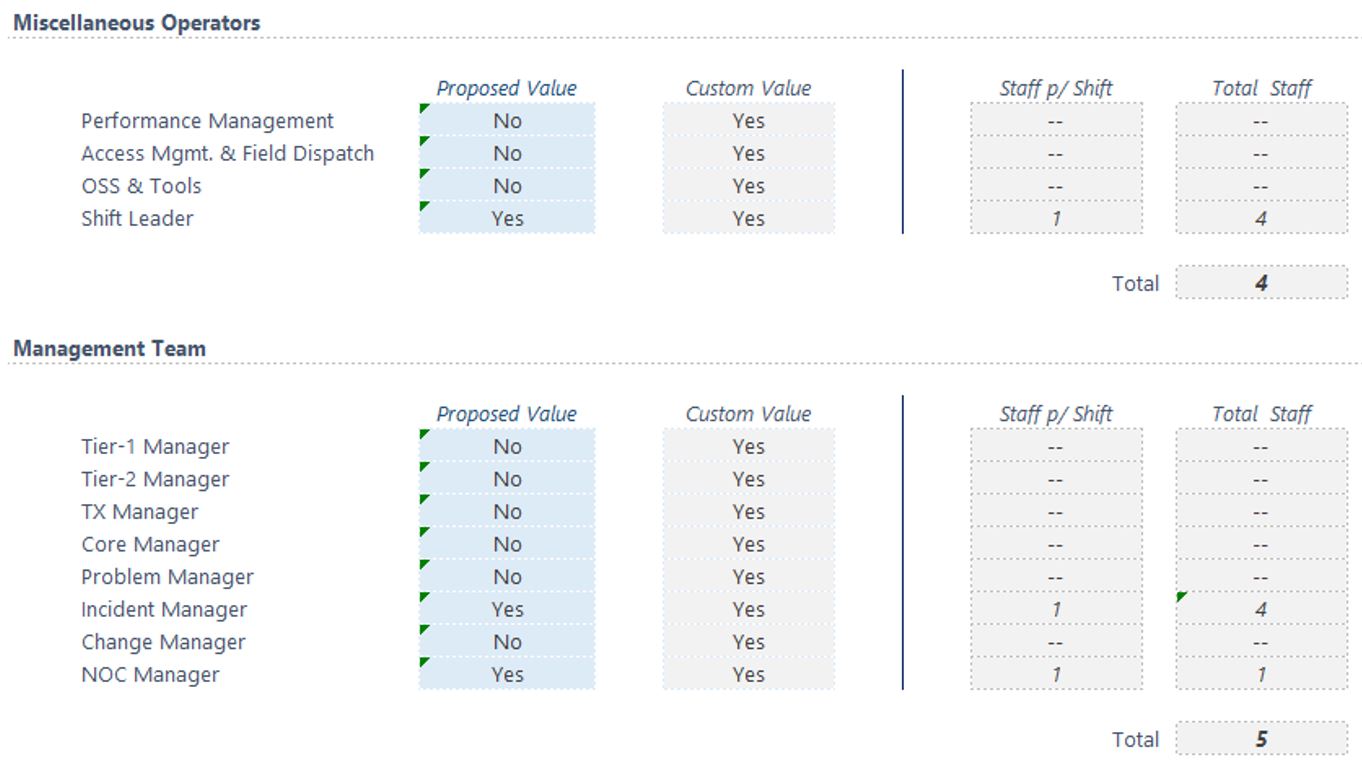
Figure 15 — Miscellaneous operators and management team
It is important to note that the additional staff resources due to number of MNOs will not greatly impact on the overall quantity. An additional 10% per MNO should suffice to cope with the demands of the MNOs.
Finally, it is worth mentioning that the tool is provided in Excel format which enables the NaaS Operator to change the underlying dimensioning assumptions based on their own experience or estimates.
6.5 Facility Design & Sizing
To dimension the NOC facility the NaaS operator must consider the peak number of resources that will be working on the NOC premises, according to the dimensioning performed on the previous section.
Through facility sizing the NaaS operator will be able to estimate office space, office equipment and networking and switching infrastructure, including office space that will be occupied, number of meeting/situation rooms needed, number of restrooms, laptops, screens, desks, chairs, and routing and switching equipment/ports.
Regarding the office space, it is important to consider that access and security infrastructure will be needed, as well as proper electrical/power distribution to be analyzed to offer a high availability solution in case of a power outage.
The NOC dimensioning tool can be used for facility dimensioning based on the headcount for the NOC team, as shown in Figure 16:
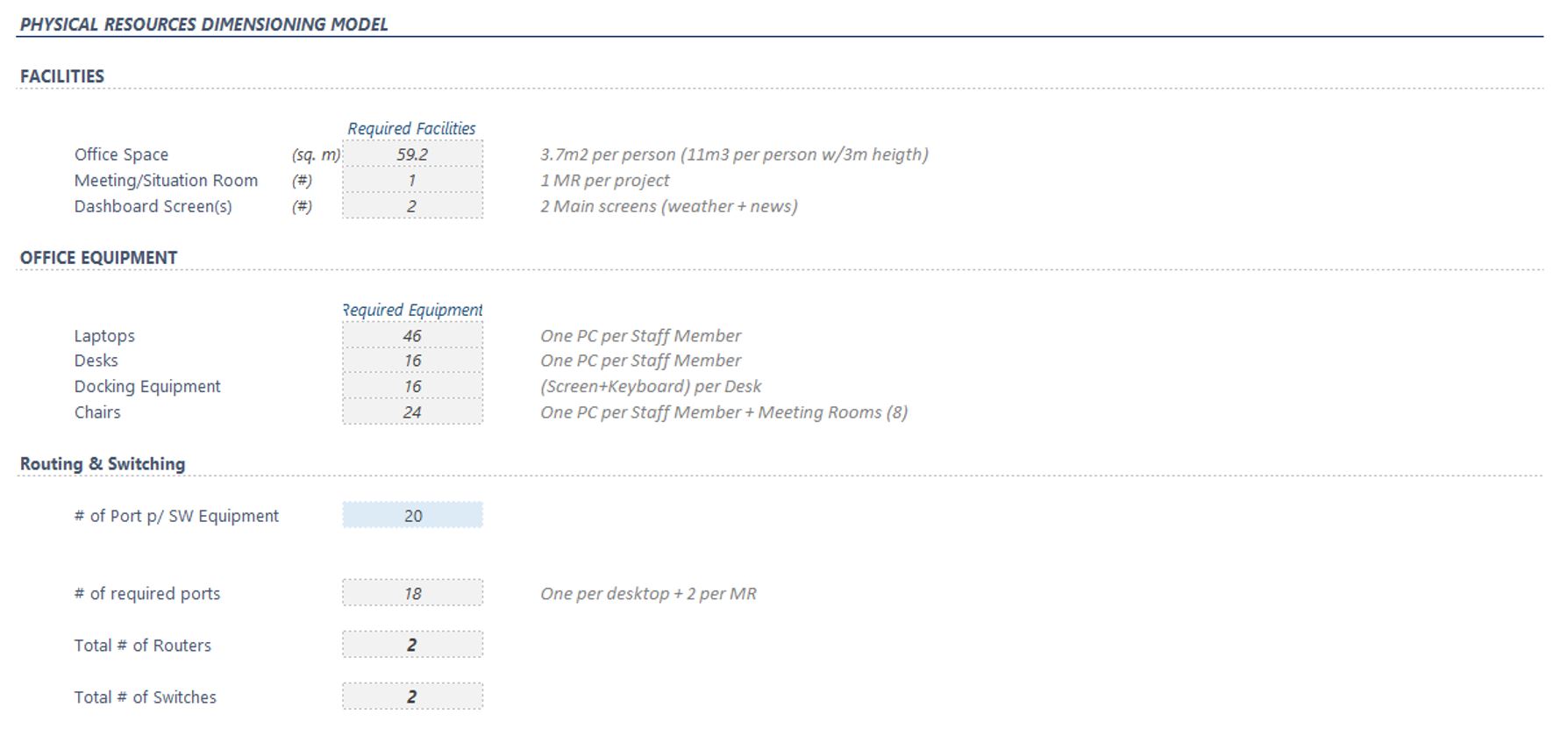
Figure 16 — Playbook NOC dimensioning: tool facility sizing