
Network as a Service (NaaS) PlayBook
1. SOC Introduction
The service operation center (SOC) is a highly specialized area that focuses on improving the availability, performance, and integrity of network services, managing the End-to-End (E2E) customer experience. SOC services and/or responsibilities include, amongst others:
This module presents an introduction to the functions, processes and tools that operate within a SOC, establishing guidelines for the NaaS operator to define the structure of their own SOC, customize the processes to be implemented, evaluate and select the tools to support the operation, and choose the implementation model to be followed along with the dimensioning of the SOC team and facilities.
1.1 Module Objectives
This module will immerse the NaaS operator into the functions and processes of the SOC and will provide the necessary directions to define processes and resources for the NaaS operator SOC. The specific objectives of this module are to:
1.2 Module Framework
The module framework in Figure 1 describes the structure, interactions, and dependencies among different NaaS operator areas.
Operations & maintenance stream comes after network deployment to oversee and support the ongoing operation of the network, supported by supply chain management. The SOC aims to transform operations from network-oriented to service- and customer-oriented. It coordinates with the NOC and amplifies its scope, as depicted in Figure 1.
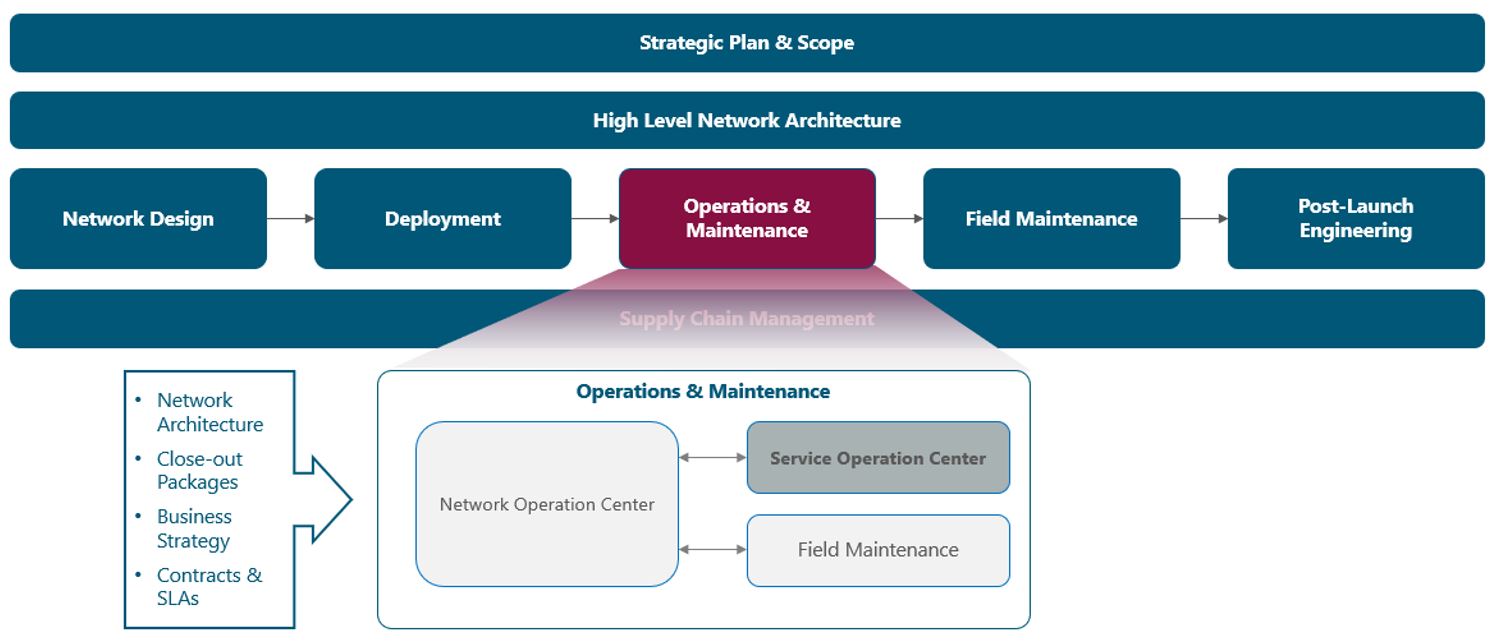
Figure 1 — Module Framework
Figure 2 presents a functional view of the SOC module where the main functional components are exhibited, along with the common functions the SOC shares with the NOC. Each function and its processes are discussed in sections 3 and 4, while a high-level view on systems is provided in section 5. It is important to note that not all NaaS operators will implement a SOC, depending on their business strategy, service offering, and budget constraints. Further guidance is provided in section 2.
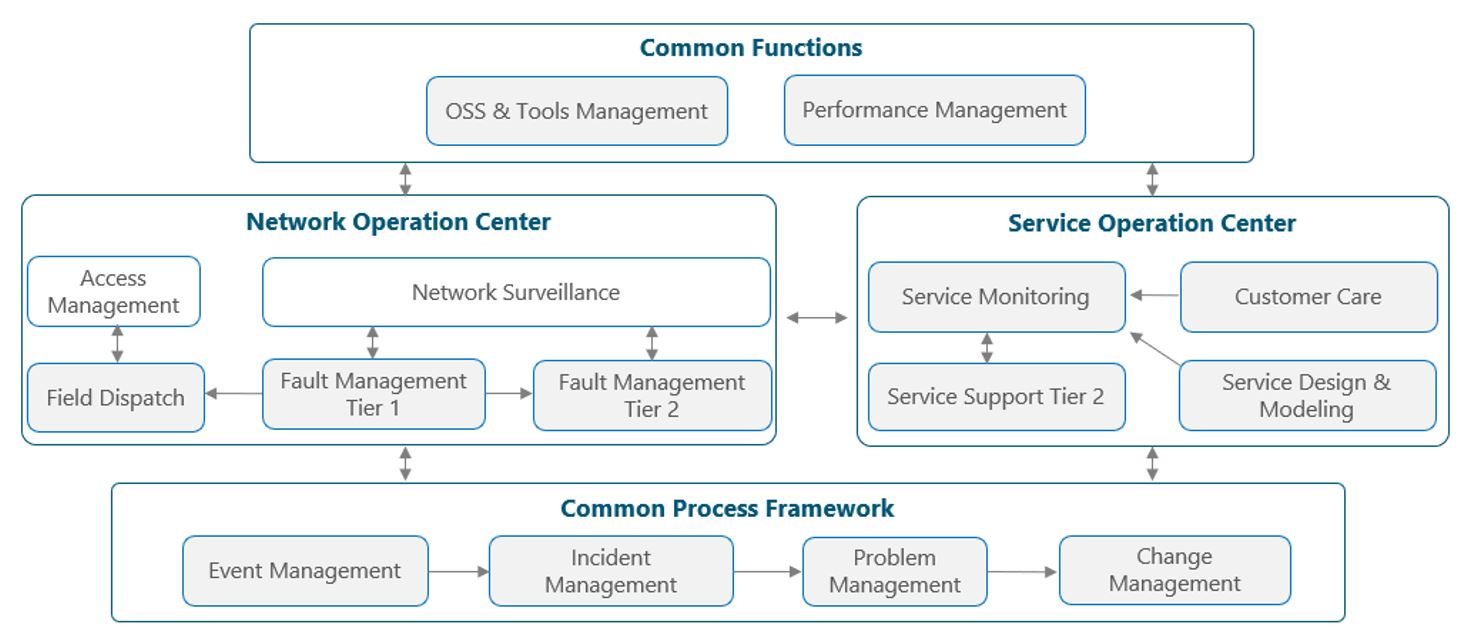
Figure 2 — Service Operations Center Functional View
The rest of this module is structured as follows: section 2 provides the fundamentals of the SOC organization. Section 3 focuses on the functional aspects of the SOC and provides customization options. Section 4 discusses the processes that are typically established on the SOC and offers process selection and configuration analysis. Section 5 provides a high-level view of the systems and tools commonly used on a SOC. Finally, Section 6 provides guidance for NaaS operators to define the model and resources to be incorporated into its SOC solution.
2. SOC Fundamentals
This section presents an overview of the SOC, including the organization structure, the coordination with the NOC, and the scope for each team, highlighting relevance and potential impact for NaaS operators.
2.1 SOC Overview
A SOC is often seen as an evolution from the NOC. The NOC’s objective is to monitor the performance of the network by rectifying equipment/transmission/power faults. This is the network-centric approach that is originally associated with the NOC organization. The NOC is mainly measured by the availability and performance of the overall network.
However, to differentiate in the marketplace, network operators saw the need to deliver superior services to their subscribers. Thus, the SOC aims to transition from network-centric operations to service-centric operations: instead of optimizing the network for improved performance per network domain alone, service-centric operations aim to optimize the network for improved performance across each service.
The SOC main responsibilities include:
As stated before, the objective of a SOC is to transform operations from network-oriented to service- and customer-centric. This is enabled by modeling and developing an E2E view of key prioritized services which drive customer experience (e.g., mobile data speed) and then driving proactive operational actions based on real-time service and customer insights, focusing on the correlation of service performance alerts, network element faults and probing data to quickly locate issues, prioritizing workload based on service impact and affected customers.
Such a transformed approach helps to diagnose and restore network service degradations faster, and aids to identify areas of potential capacity constraints therefore improving service usage due to higher accessibility and quality.
While the NOC delivers an operational business impact (ensuring network uptime, reducing mean-time-to-restore (MTTR) for network faults and improving geographical coverage), the SOC delivers a strategic business impact by reducing potential revenue loss and improving customer satisfaction.
It’s important to mention that the SOC organization depends on the NOC, which functions as the baseline for all network activities, and the SOC feeds from network status and conditions provided by the NOC to improve customer experience. The operator can always choose to have a NOC organization alone, especially for small-sized networks, in financially constrained environments, and/or when the NaaS operator does not implement the E2E service.
However, if the NaaS operator decides not to implement a SOC solution from the start of operations, the SOC solution can be implemented afterward if demanded by customer MNOs or to improve performance after the NaaS operator has positioned in the market.
2.2 SOC Organization
From a functional view, the SOC includes the following services:
In addition, the SOC shares the following services with the NOC:
All these functions will be covered in depth in section 3, where guidance is provided for the NaaS operator to define the structure that best matches the intended scope of the organization.
From a process view, the SOC includes the following responsibilities:
These processes will be covered in depth in section 4 of this module. NaaS operators will be presented with alternatives to customize the processes according to their requirements and capabilities.
The teams working within the SOC organization coordinate their efforts in order to prevent or minimize any degradation or reduction in the quality of the service delivered to the end user. While the E2E flow will be presented in Section 4, a high-level overview of the interactions of the teams is presented below:
Throughout this module, NaaS operators will be able to examine the different scenarios and select which functions could be merged in their operation according to their scope.
3. SOC Functions
This section analyzes the SOC from a functional level, including focus on its vital aspects and the different configuration possibilities for the NaaS operator.
3.1 SOC Functions Overview
In the following subsections, the description for each function of the SOC is presented along with an analysis of the primary success factors and relevance/need for each function, highlighting the functions that are shared with the NOC.
3.1.1 Service Design and Modeling
Service design and modeling is the first function that must be executed in a SOC, as the services that will be monitored need to be first defined, along with their key performance indicators (KPIs), and then modeled into a tool for monitoring and trending purposes. A recommendation for the NaaS operator is to revisit section 2.2 of the Network Monitoring Architecture module for a list of KPIs to take into consideration, which may include:
Such KPIs are used to model the service and in turn, for monitoring and analysis purposes.
Services definition is based on the commercial strategy and network architecture/capabilities of the NaaS operator. The first step is to define the type of traffic (i.e., data, voice, video, IoT). Then, for each type of traffic, services can be further differentiated based on the following attributes:
Table 1 provides examples of KPI definitions for data services:
|
KPI |
Service |
|||
|
MNO Best Effort 4G Data |
MVNO Best Effort 4G Data |
MNO Priority 4G Data |
MVNO Priority 4G Data |
|
|
Monthly availability |
99.50% |
99.50% |
99.90% |
99.90% |
|
Latency |
60 ms |
80 ms |
40 ms |
50 ms |
|
User DL throughput |
4 Mbit/s |
4 Mbit/s |
8 Mbit/s |
8 Mbit/s |
|
User UL throughput |
1 Mbit/s |
1 Mbit/s |
1.5 Mbit/s |
1.5 Mbit/s |
|
Packet loss rate |
1% |
1% |
0.05% |
0.10% |
|
Monthly traffic volume per subscriber |
2 GB |
2.5 GB |
5 GB |
5 GB |
|
E-RAB establishment success rate |
98% |
98% |
99% |
99% |
|
EPS attach success rate |
95% |
95% |
98% |
98% |
|
E-RAB drop rate |
2% |
2% |
1% |
1% |
Table 1 — Example KPIs for data services.
The main activities involved in service design and modeling include:
All the selected KPIs for each service must be analyzed from an E2E perspective, and monitoring data sources must be evaluated and selected. The data must then be integrated into the network monitoring or service quality management tool ‘ which will be described in section 5. The service monitoring team must understand and accept the model for each service in order to perform monitoring, trending, and reporting.
As this function is only executed on-demand, its performance is not evaluated against hard metrics. However, if deemed convenient by the NaaS operator, the following metrics can be used for this purpose:
3.1.2 Service Monitoring
Service monitoring is the most vital function that is supported by the SOC. SOC staff monitors service trends, dashboards or reports made available to them, using available tools like a network performance management system or a service quality management tool.
Once a service degradation is detected, SOC staff conducts preliminary filtering (e.g., correlation to active cases, correlation to faults detected by the NOC), opens the corresponding TT, categorizes/prioritizes the ticket severity and handles the case escalation according to defined procedures.
Service monitoring function typically includes the following activities:
Service monitoring must be one of the first functions to be executed as it’s the basis or trigger for several other functions, similar to the network surveillance function in the NOC. It is the first entry point for service status and enables responses in a timely manner which effectively contributes to improving overall restoration times.
This function is supported through various software solutions as detailed in section 5. Current solutions for service monitoring provide automation of certain monitoring tasks, enabling SOC technicians to be more efficient regarding service degradation identification, filtering, correlation, and integration with other processes; some solutions may even incorporate analytics to facilitate diagnosis. It is important for NaaS operators to analyze these solutions and consider the trade-off between the efficiency and the cost of most sophisticated solutions.
Typical metrics used to evaluate the performance of this function are:
3.1.3 Service Support Tier 2
Service support tier 2 resolves service degradations escalated by the service monitoring team. If a fault cannot be solved by the service tier 2 staff, it will be escalated to tier 3 support (e.g., customer support, technical assistance center, vendor support).
The main activities performed by this function are:
This specific function is assigned to a group of people whose expertise is broader and deeper than the service monitoring team. This team usually works cases that the previous team was not able to diagnose, escalates cases to level-3 support (e.g., vendor support) and supervises the diagnosis, troubleshooting and resolution of high-severity scenarios. This team is normally broken into domain segments, which are known as domain technical experts for RAN, TX, and CORE.
Having a service tier 2 team helps the organization by lowering resolution times for complex cases. The absence of this team implies that cases need to be escalated to vendor support directly by the service monitoring team, thus increasing the time and cost to resolve the incident.
Analytics and automation tools commercially available (see section 5) provide robust support for this function, which can improve the efficiency of the service tier 2 team, reducing the size or even giving the possibility to merge this function with service monitoring as discussed in section 3.2.
Generally used metrics to evaluate this function are:
3.1.4 Customer Care
The customer care team serves as the first point of contact where all service-related queries from end customers are concentrated. This team reviews, analyzes and organizes all end customer problems and provides standard resolutions for simple service requests.
The main activities performed by this function include:
A customer care team helps the organization by receiving, categorizing, and filtering end customer queries, enabling the teams to focus on relevant issues on the network and services.
The most often used metrics to evaluate this function are:
3.1.5 Performance Management
This function consists of identifying performance-related issues for network elements and ensuring they are correctly prioritized and managed until proper resolution. Performance management includes the analysis and reporting of network and service quality measures. This function is shared with the NOC organization; thus, the Performance Management team reports on performance to both the NOC and SOC organizations as required. Further details on this function can be found in section 3.1.4 of the NOC module.
3.1.6 OSS & Tools Management
OSS & tools team is the administrative entity for all OSS, EMS and NOC tools that are deployed for network management. OSS Management includes the analysis and reporting of OSS quality measures. This function is shared with the NOC organization; thus, the OSS & tools management team will oversee all tools being utilized for both teams. Further details on this function can be found in section 3.1.5 of the NOC Module.
3.2 SOC Functions Selection & Customization
This section examines the alternatives for the definition of the functions to be deployed on the SOC organization, based on the NaaS operator scope and needs.
3.2.1 SOC Tier 1 Setup
3.2.1.1 Customer Care + Service Monitoring Scenario
Aggregating functions for a team within a department or organization is a way to customize such an entity, usually looking for optimization opportunities. One alternative for aggregation of functions for a SOC organization is performed at the SOC tier 1 level.
As the customer care team is the first point of contact for all end customer queries, serving as a service desk solution for the SOC organization, and the service monitoring team is aware of all service degradations being investigated, both functions can be incorporated into one single entity.
This group of people will be in charge of performing real-time monitoring of services, create TTs, perform first-level analysis and diagnosis, and escalate the ticket to the corresponding fix agent if unable to resolve, while also receiving and responding to end customer queries or complaints. This structure enables faster responses for end customer queries as the team is aware of all service degradation conditions on the network.
The NaaS operator can choose this option if a high volume of calls or customer queries is not expected, since an overflow of customer complaints could jeopardize the monitoring function. In addition, if the NaaS operator seeks to improve resolution times, this option is also a good choice since the same group that is monitoring services responds directly to customers, skipping the communication lapses that normally occur when the functions are separated on different teams.
Another possibility is to consider the automation of certain functions related to customer care and service monitoring through available tools in the market. If this is done the right way, resources can handle both customer care and service monitoring even for a high volume of customer queries.
3.2.1.2 Service Monitoring + Service Support Tier 2
A second alternative for aggregation of functions is incorporating the service monitoring and the service support tier 2 functions in one single team, creating as such one single instance that will be in charge of all service-related cases that are identified on the network. This team would then be in charge of performing real-time monitoring of services, creating trouble tickets, performing first and second level analysis and diagnosis, and escalating the ticket to the vendor’s support team directly if they are unable to resolve the case.
This setup requires engineers with a tier 2 profile, since a higher level of expertise is required for the engineers assigned for this team.
This option is only recommended for small networks where a few services (no more than three) will be monitored, as there would be just one entity within the SOC structure monitoring such services and performing analysis and diagnosis on open cases. Having a varied set of services may compromise the team effectiveness. However, if analytics and automation tools are implemented, this option can still be considered due to the efficiencies obtained through these tools.
Table 2 shows a summary of the scenarios that were covered on the previous sections:
|
SOC Tier 1 Setup |
FUNCTIONS |
Applicability |
||
|
Customer Care |
Service Monitoring |
Service Support Tier 2 |
||
|
Customer care + service monitoring |
✔ |
✔ |
Small networks with a high volume of call or customer queries not expected |
|
|
Service monitoring + service support tier 2 |
✔ |
✔ |
Small-to-medium network with a few services being monitored and relaxed service level agreements |
|
Table 2 — SOC tier 1 scenarios
3.2.2 Service Support Tier 2 Setup
3.2.2.1 Service Support Tier 2 + Performance Scenario
Aggregation schemes can be performed at the service support tier 2 level, most notably incorporating the performance management function into the service support tier 2 responsibilities, which comprises domain-specific expertise analysis and diagnosis for service degradations, or escalations to vendor support for complex cases.
Under this configuration, the tier 2 group will respond both to service and network performance queries coming from the NOC and SOC teams.
This option can be chosen by the NaaS operator if their SOC solution models services very close to network performance indicators and in networks that are looking for optimization opportunities within their NOC/SOC structure due to budget constraints.
3.2.2.2 Service Design and Modeling + Service Support Tier 2 Scenario
Another common setup is to aggregate the service design/modeling and service support tier 2 functions. In this way, the domain technical experts periodically set and review the services that will be incorporated and monitored as part of the overall SOC solution. With this scheme in place, the same group that designed and modeled the service in the first steps of the SOC build will be in charge of providing second-level support for the SOC tier 1 team.
Table 3 summarizes the scenarios covered above for the service support tier 2 team.
|
Service Support Tier 2 Setup |
FUNCTIONS |
Applicability |
||
|
Service Support Tier 2 |
Performance Management |
Service Design & Modeling |
||
|
Service support tier 2 + performance |
✔ |
✔ |
Services modeled closely to network performance indicators |
|
|
Service design and modeling + service support tier 2 |
✔ |
✔ |
✔ |
Better support and understanding of the services with relatively small changes in service design and modeling |
Table 3 — Service support tier 2 scenarios.
3.2.3 SOC Leadership
SOC leadership duties include SOC planning, controlling, steering, and reporting all aspects of SOC activities; management of SOC organization and SOC staffing; delegation and empowerment of SOC managers and team members. As the SOC is a solution that is built upon the NOC, there is a very close relationship between the leadership structure of both groups. The following main activities are performed by the SOC leadership team:
Figure 3 shows the most common structure for SOC and NOC Leadership, which will be explained in detail in the following paragraphs:
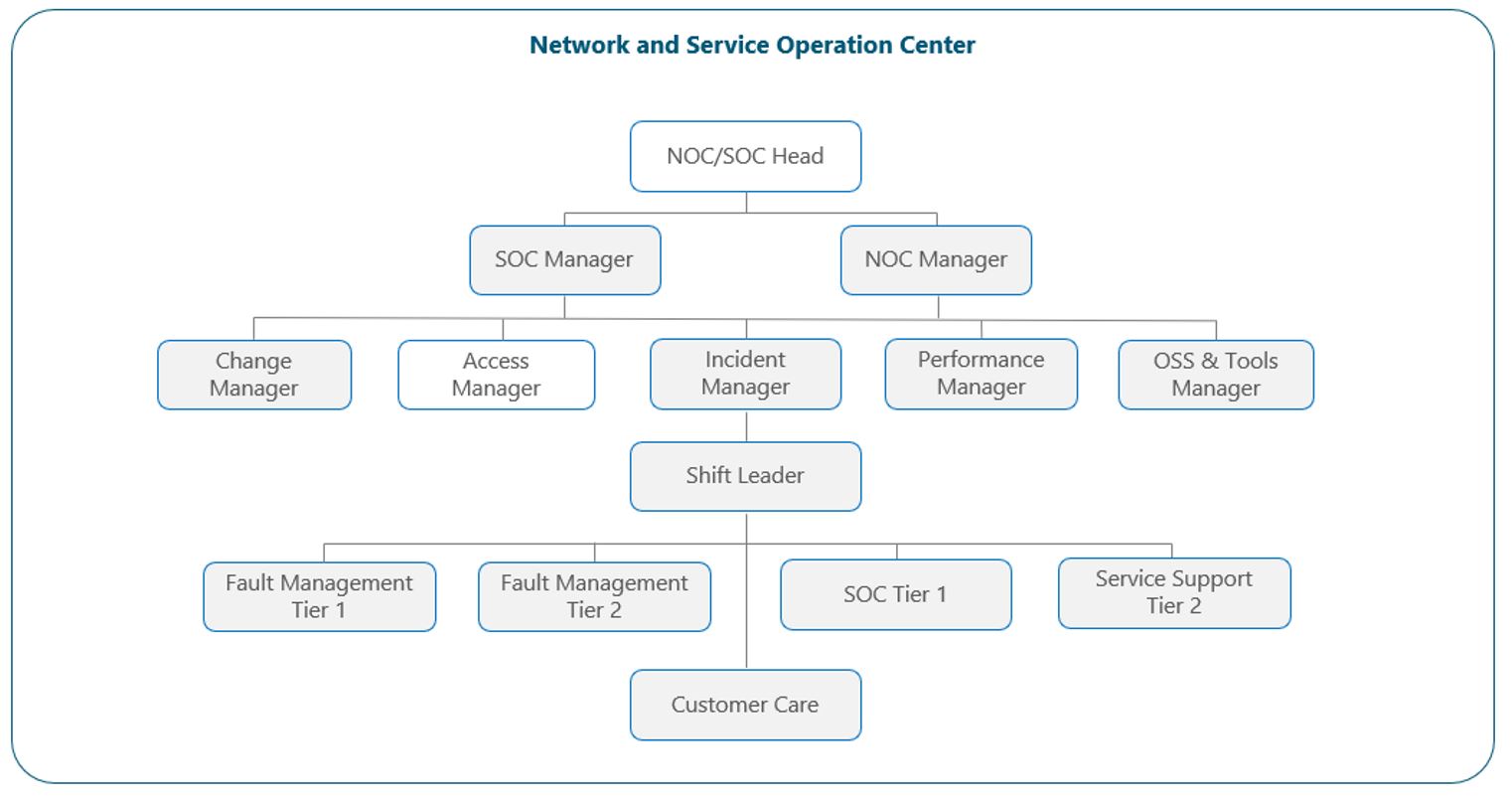
Figure 3 — NOC and SOC leadership view.
As explained in the NOC module, each NOC group is usually supervised by a manager who delivers guidance to the entire team and serves as the point of contact (POC) for all the requirements or escalations towards that team. The SOC main POC is the SOC manager who is usually in charge of all the SOC structure, including the customer care, SOC tier 1 and service support tier 2 teams. For large-sized operators, the customer care team may have a direct manager supervising all the team’s activities. The entire team is supervised by a NOC/SOC Head, who acts as the ultimate responsible for the NOC and SOC operations.
Team/shift leaders are regularly set as part of the structure (having at least one team leader per shift). These people are trained engineers whose expertise and process knowledge, supported by leadership empowerment, enables them to make controlled operative decisions during their shift in absence of the team manager. Shift leaders usually respond to the acting incident manager on duty, who is the highest-ranking officer for any operative decision, regardless of the network or service nature it may arise from.
The NOC/SOC team configuration is further discussed in Section 6, in which the model to be implemented and the team design and dimensioning are presented.
4. SOC Processes
This section provides an examination of the core processes followed by the SOC and their interactions with the NOC including E2E process flows, key elements, roles and responsibilities and the most common metrics used to measure each process success. Guidance for the NaaS operator SOC processes customization is provided throughout the section.
4.1 SOC Processes Analysis
In the following sections, the processes executed at the SOC are presented including the rationale, common KPIs, and roles associated with each process.
4.1.1 Service Event Management
Similar to the network event management process performed by the NOC (see NOC Module), the SOC implements a service event management process in coordination with the NOC. Figure 4 presents the high-level, E2E process flow for service event management which is also provided as a template for NaaS operator customization. The green dots on the left indicate input triggers to the process and the red dots are end points of the process.
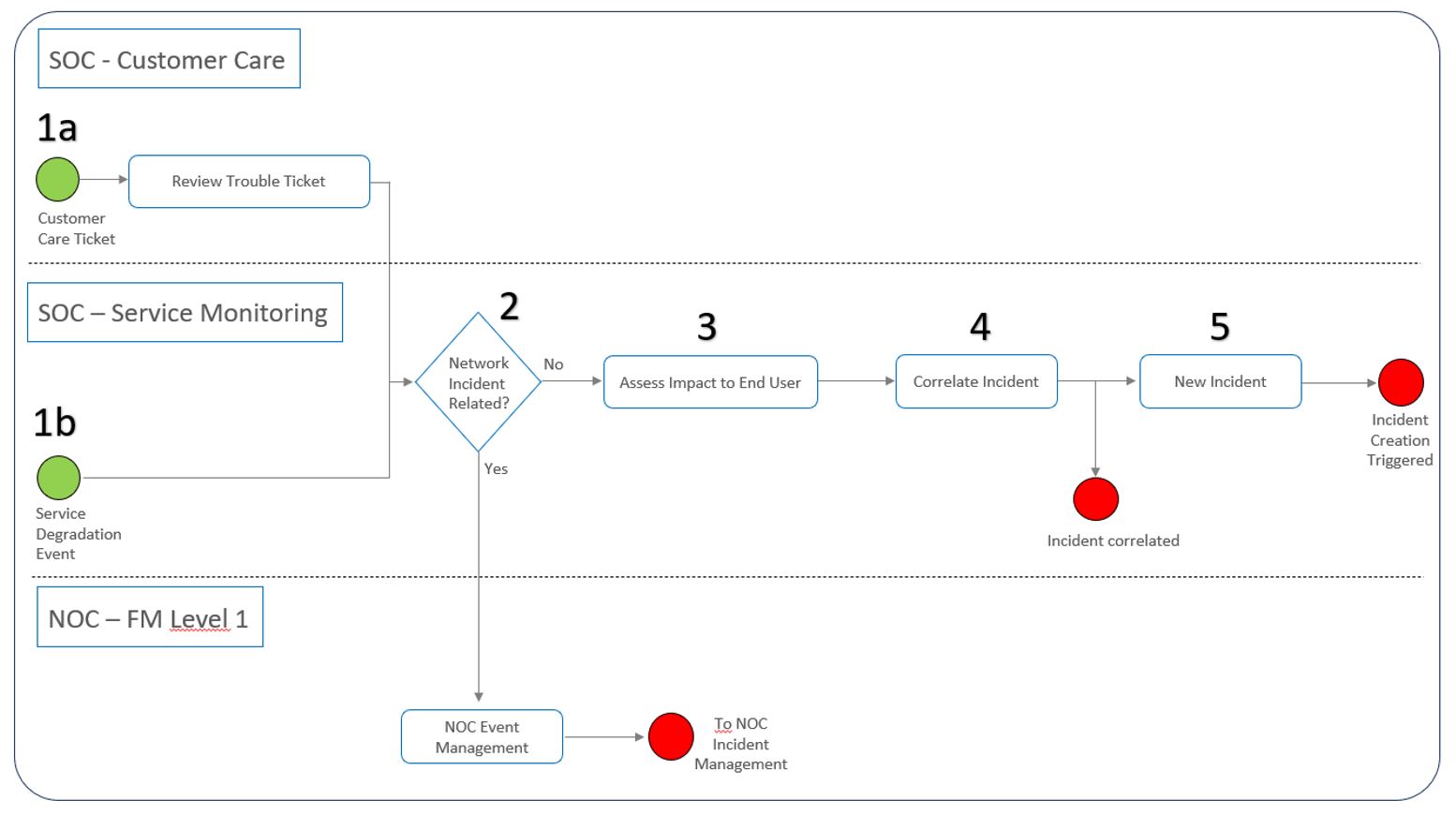
Figure 4 — Service event management high-level flowchart
Below, the process is described in detail:
Both the NOC and SOC event management processes may run in parallel, each one activated by its own triggers ‘ service degradations in the case of the SOC, and network faults/alarms in the case of the NOC. The SOC event management process stops when the service degradation detected is derived from a fault/alarm that has already been acknowledged from the NOC and will be resolved by the NOC incident management process.
Event Management is typically measured by two KPIs:
4.1.2 Service Incident Management
Definitions presented for the incident management process in the NOC Module are applicable for the service incident management process.
The high level, E2E process flow for service incident management is presented in Figure 5 below and provided as a template for NaaS operator customization:
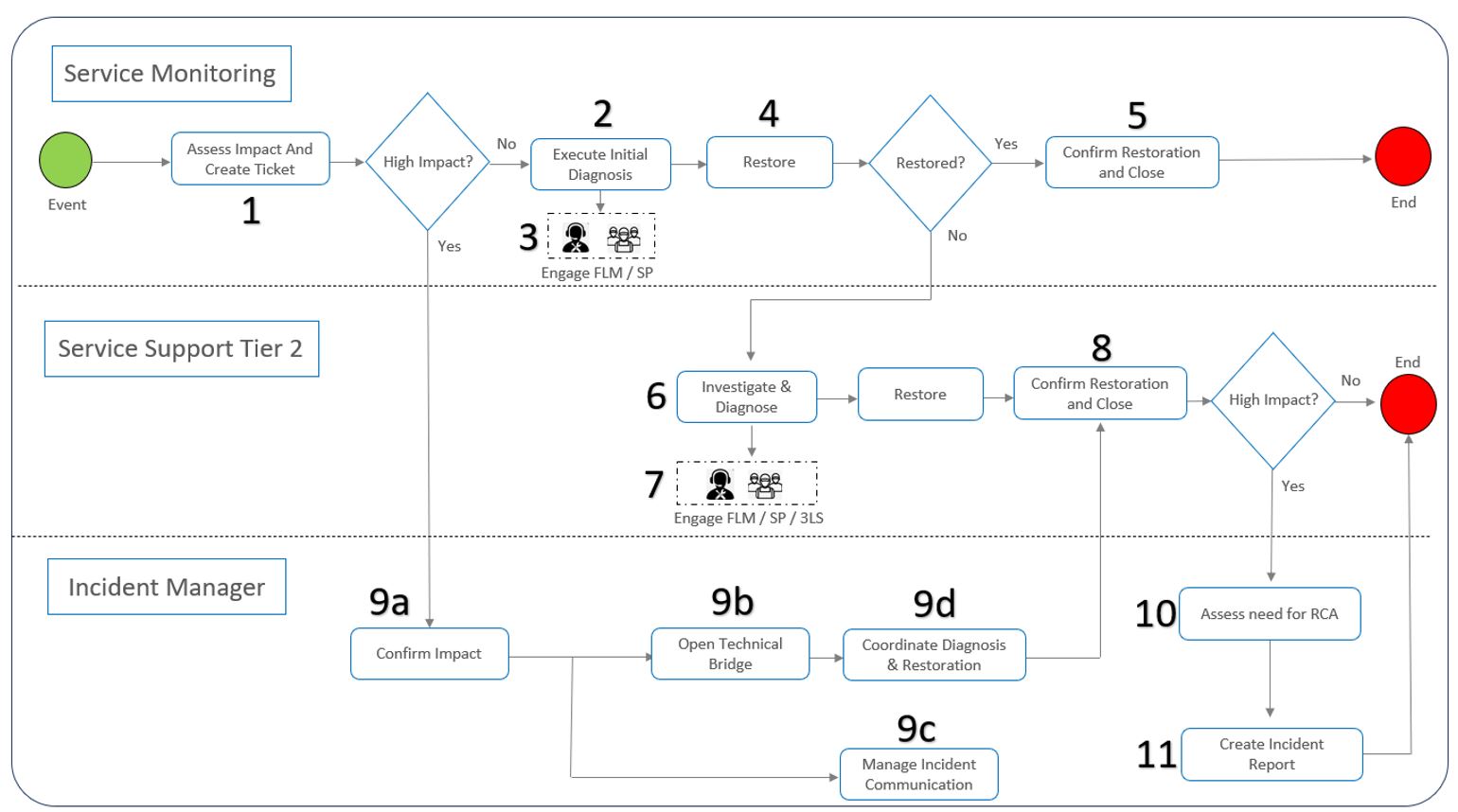 Figure 5 — Service incident management high-level flowchart
Figure 5 — Service incident management high-level flowchart
As can be seen, the process is identical to that for the NOC with the sole difference that for service incidents, the FM level 1 role is taken by service monitoring and the FM level 2 role is taken by service support tier 2. Thus, further details can be found in the NOC Module.
In addition, as seen before on the SOC event management process section, both the NOC and the SOC may respond to events in the network, each one activated by its own triggers, but the SOC process will stop when the service degradation is attributable to network faults or alarms. In this scenario, the NOC incident management process ‘ which is fully covered in the NOC Module in section 4.1.2 — will take over taking into account the number of users and the type of services impacted by the network event.
4.1.3 Service Problem Management
The service problem management process follows the same flow and KPIs of the problem management process included in the NOC Module in section 4.1.3. In fact, the problem management process is independent of the flow that activates it, i.e., the process is the same, what changes is the trigger of the process which can be a network incident or a service incident.
4.1.4 Service Change Management
In a similar vein, the service change management process follows the same flow and KPIs of the change management process detailed in the NOC Module in section 4.1.4. Change management process is independent of the flow that activates it, i.e., the process is the same whether it’s triggered within the NOC or SOC organization.
4.2 SOC Process Selection & Configuration
Now that the NOC processes have been analyzed the NaaS operator must select the processes to be implemented based on the NOC scope and NaaS operator capabilities or requirements.
Event management, incident management and change management are mandatory processes for a NOC/SOC operation. Still, there are three process adjustments that may be considered by the NaaS operator:
If the process is implemented for the SOC, and the process is also in place for the NOC, the recommendation for the NaaS operator is to have a single problem manager that handles both NOC and SOC problem tickets.
5. Systems & Tools Overview
This section provides an examination of the systems and the most common tools used to support the SOC activities.
5.1 Tools High Level View
There are several tools commonly used by a SOC to achieve its objectives. The most widely used are the service desk management (SDM) tool (which is also used by the NOC organization), a network performance management (NPM) system (which is an optional tool for the NOC), and a service quality management (SQM) tool.
The SDM tool is a mandatory tool for the SOC (as it is the case with the NOC), and both the NPM and the SQM tools can be regarded as optional tools for the SOC. An overview of these tools is presented in the following sections.
5.1.1 Service Desk Management Tool
This tool is used for the documentation of all incidents, problems and changes that are being worked on the network at any given time. It can be considered one of the main tools used by the NOC and the SOC as well, as it enables the teams of both organizations to have a proper mechanism to document all activities surrounding each incident, problem, or change ticket. For details on usage, features, and examples of this type of tool refer to section 5.1.1 of the NOC Module.
It’s worth noting that a robust SDM tool that supports standardized interfaces is the first step toward SOC process automation. Thus, the NaaS operator should consider the tradeoffs between additional cost of such a tool and the operational expenses due to manual processes.
5.1.2 Network Performance Management System
This tool aids the NOC and SOC organizations to monitor the performance of the network in a more accessible manner. This is strategic for teams focusing on network KPIs or for teams investigating service degradations before they are reported by end users. Further details on the usage, features, and examples of this type of tool are provided in section 5.1.4 of the NOC Module.
5.1.3 Service Quality Management Tool
This particular tool is incorporated only by operators opting for a SOC solution. This tool aids the SOC organization to manage the quality of services delivered to end customers according to their expectations by assessing how well a service is being delivered, so as to improve its quality by identifying problems and correcting them to increase customer satisfaction.
This type of tool enables the SOC teams to supervise services in almost real-time, regardless of vendors or technologies incorporated in the network ecosystem. An SQM tool consolidates all the information coming from call detail records (CDR), network performance counters, subscriber data from the HLR/HSS (e.g., profile, type of services contracted, restrictions), billing support systems, network service impacting alarms, and other sources, transforming all the different inputs into meaningful KPIs and key quality indicators (KQIs). This enables the SOC team to analyze a service from different angles including geographical references.
Most advanced tools incorporate in addition, analytics and automation capabilities which can greatly improve the efficiency of the SOC teams.
Table 4 provides examples of commercial SQM tools. Currently there are no open source or free tools that offer the same level of information and features as the commercially available SQM tools. This is mainly attributable to the complexity of the data that must be manipulated and the closed source nature of the information, as most of the input comes from proprietary systems.
|
Commercial Tools |
|
Nokia Wireless Network Guardian (WNG) |
|
Ericsson Expert Analytics |
|
Comarch Service Quality Management |
|
IBM Tivoli Service Quality Management Center |
Table 4 — Commercial Service Quality Management Tools
5.2 Systems Selection
In the previous section the tools that may be part of the SOC were introduced. Now, aspects to consider for tool evaluation and selection will be presented. First, the critical operational tools will be discussed, followed by optional support tools.
5.2.1 Critical Operational Tools
There is a tool that is critical and needs to be part of the Service Operation Center solution incorporated by the NaaS operator: The SDM tool, as it is vital for the incident management process. This tool is also critical for the NOC team.
A full SDM tool can be of great aid for the SOC team, as it would benefit from having all associated tickets in one single tool (incident management, problem management, change management). This translates into a more agile organization, as all teams ‘speak’ the same language and know the same reference.
As mentioned before, there are free SDM tools available in the market, and some of them have open trials that can benefit a starting organization as the team can get used to the interface and the way of working before considering some of the commercial offerings surrounding such tools.
One important factor to consider for the SDM tool incorporation is to review the actual processes that will be run by the NOC and the SOC. While these organizations will adhere to some form of event, incident and change management, there is an area that needs to be reviewed like problem management.
If the organization won’t consider having this process in place, both problem tickets and the need for a knowledge base can be set aside, lessening the need for a full SDM tool. There are some organizations that use simpler tools like Microsoft Excel for change management ‘keeping records and control of all change activities’ and incident management can be realized via a simpler ticketing system, which can also be used by the customer care team if such function is incorporated into the SOC solution.
5.2.2 Support Tools
In the following paragraphs NPM and SQM tools will be discussed, which are support tools that are optional depending on the needs of the NaaS operator.
An NPM tool brings value to an organization that considers performance management as one of their core functions. This type of tools can be greatly beneficial for a SOC team as they enable organizations to be aware of performance degradations as they occur, and often aid such investigations speeding up resolution times.
This tool may be used as an alternative if the NaaS operator implements a SOC solution but does not incorporate a SQM tool. This option can be chosen by the NaaS operator if their SOC solution models services very close to network performance indicators.
If the NaaS operator decides to start operations without such focus on performance management, then the use of this tool becomes obsolete for the NOC and SOC organizations. This scenario could be present if the NaaS operator chooses to focus on fault management alone restoring faults on the network (in the case of the NOC) and on service degradations that have an impact on end customer service (in the case of the SOC).
The NaaS operator could choose to focus on network/service performance on a possible later phase, once the NOC and SOC teams are more mature, as the detection and restoral of performance scenarios are typically more oriented to RF or optimization teams and require a more mature operation for increased success. The absence of RF or optimization teams within the operator ecosystem may also be a reason to avoid the implementation of this kind of tool.
This tool can enable the SOC team to become highly effective in several areas such as monitoring, analysis and troubleshooting of service degradations. Still, the costs associated with this tool such as acquisition, configuration or maintenance may be dimmed as too high by the NaaS operator, especially in the absence of open source or free alternatives.
As mentioned earlier, in such a scenario, the NaaS Operator may choose to have the NPM tool as an alternative. The operator is encouraged to choose at least one of the support tools incorporated into their SOC solution. While the SQM tool is a far more suitable tool for a SOC, the organization can have the NPM tool as a more feasible, low-cost tool that the SOC can utilize for service degradation detection and analysis.
In any case, the NaaS operator must be aware that E2E session visibility will be required to adequately manage service quality. This implies the capability to capture packets at key interfaces of the network, which can be achieved ‘as detailed in the network monitoring architecture module‘ through probing solutions or through inbuilt packet capture capabilities in the network equipment. Thus, it is recommended that the NaaS operator incorporates these requirements as part of the RFP for network equipment and/or network monitoring solutions.
6. SOC Implementation
This section presents a discussion of the available implementation options and directives for NaaS operators to define their own staffing model, service levels, and dimensioning of the SOC staff and facility.
Staffing Model Assessment
There are two main models available for NOC and SOC staffing that can be considered by the NaaS operator: in-sourcing (building the NOC and SOC with internal resources as part of the NaaS organization) and out-sourcing (reaching out to a third party to take control of operations). ‘An optional third alternative is also available, in which the NaaS operator may choose to outsource some tasks while retaining the vast majority of their operations.
Please refer to section 6.1 in the NOC Module for a complete discussion on the staffing model assessment, as the three models discussed there (insourced, outsourced and mixed schema) apply as well for a SOC staffing strategy.
6.2 Service Levels Definition
Service levels specify the way that an incident is treated and the expected times for response and restoration based on the severity of the incident. Therefore, the first thing that needs to be defined by the NaaS operator is a criticality matrix which specifies the classification of incidents into categories or severities.
There are typically four severities deployed in most NOC organizations: critical, major, medium, and minor. The NaaS operator must decide which scenarios fit each category, for which an initial recommendation is provided below:
After the criticality matrix is set, the NaaS operator must set two variables for each category:
The first variable is strictly SOC dependent and is usually expressed in minutes (e.g., X minutes from service degradation to ticket creation). The second variable needs consideration of several factors, including the agreed contractual SLAs with other parties (e.g., power companies, fiber companies, tower companies, field maintenance) and their escalation paths. For instance, an operator might set the following service levels shown in Table 5.
|
Severity |
SLA |
Response Time |
SOC Time |
NaaS Operator Restoration Time |
Driver |
|
Critical |
8 hours |
15 minutes |
30 minutes |
7 hours 45 minutes |
Ticket Creation: 15 minutes | Troubleshooting: 30 minutes | Restoration Tasks: 7 hours 15 minutes |
|
Major |
12 hours |
30 minutes |
30 minutes |
11 hours |
Ticket Creation: 30 minutes | Troubleshooting: 30 minutes | Restoration Tasks: 11 hours |
|
Medium |
24 hours |
60 minutes |
60 minutes |
22 hours |
Ticket Creation: 60 minutes | Troubleshooting: 60 minutes | Restoration Tasks: 22 hours |
|
Minor |
48 hours |
2 hours |
2 hours |
44 hours |
Ticket Creation: 2 hours | Troubleshooting: 2 hours | Restoration Tasks: 44 hours |
Table 5 — Service level setting example
Team Design & Dimensioning
Once that the staffing model and the service levels have been defined, the NaaS operator must design and dimension the SOC organization which should be analyzed together with the NOC organization. The following subsections address the NOC/SOC organization design and dimensioning, respectively.
6.3.1 SOC Organization Design
The NaaS operator needs to consider, as expressed before, that the SOC solution is built upon a NOC organization. The configurations that are present for a NOC organization (which can be seen in section 6.2 of the NOC Module) are taken as a base and the SOC organization is built upon that structure to meet the SOC requirements. Both the NOC and SOC structure must be visualized for a successful NOC/SOC dimensioning strategy.
Following recommendations on section 3.2, three typical configurations for a NOC/SOC organization can be identified:
✔ Customer care team exists within the organization
✔ Service monitoring team has no additional tasks
✔ There are allocated resources for performance management (that serve both the NOC and the SOC teams)
✔ Service support tier 2 is separated into domains (RAN/TX and CORE)
✔ There is one team leader per shift (that serve both the NOC and the SOC teams)
✔ On the management side, there is one leadership position for SOC manager
✔ Please refer to section 6.2 of the NOC Module for the complete scenario of the NOC structure under this configuration
✔ Both customer care and service monitoring functions are incorporated at the service tier 1 team
✔ Service support tier 2 performs in addition performance management functions
✔ There is one team leader per shift (that serve both the NOC and the SOC teams)
✔ On the management side, there is one leadership position for SOC manager
✔ Please refer to section 6.2 of the NOC Module for the complete scenario of the NOC structure under this configuration
✔ Service monitoring and service support tier 2 functions are incorporated on a single entity
✔ There is no customer care team in the organization
✔ There is one team leader per shift (that serve both the NOC and the SOC teams)
✔ On the management side, there is a general NOC/SOC manager
✔ Please refer to section 6.2 of the NOC Module for the complete scenario of the NOC structure under this configuration
The NaaS operator can choose one of the above configurations or define a customized configuration based on their own organizational requirements and constraints. If that’s the case, the guidance in section 3.2 can be applied with such a purpose.
6.3.2 SOC Organization Dimensioning
In order to perform SOC dimensioning, several factors need to be taken into consideration:
This information will aid the operator to estimate the dimensioning of the full team. For this purpose, the SOC dimensioning tool displayed in Figure 6 is provided.
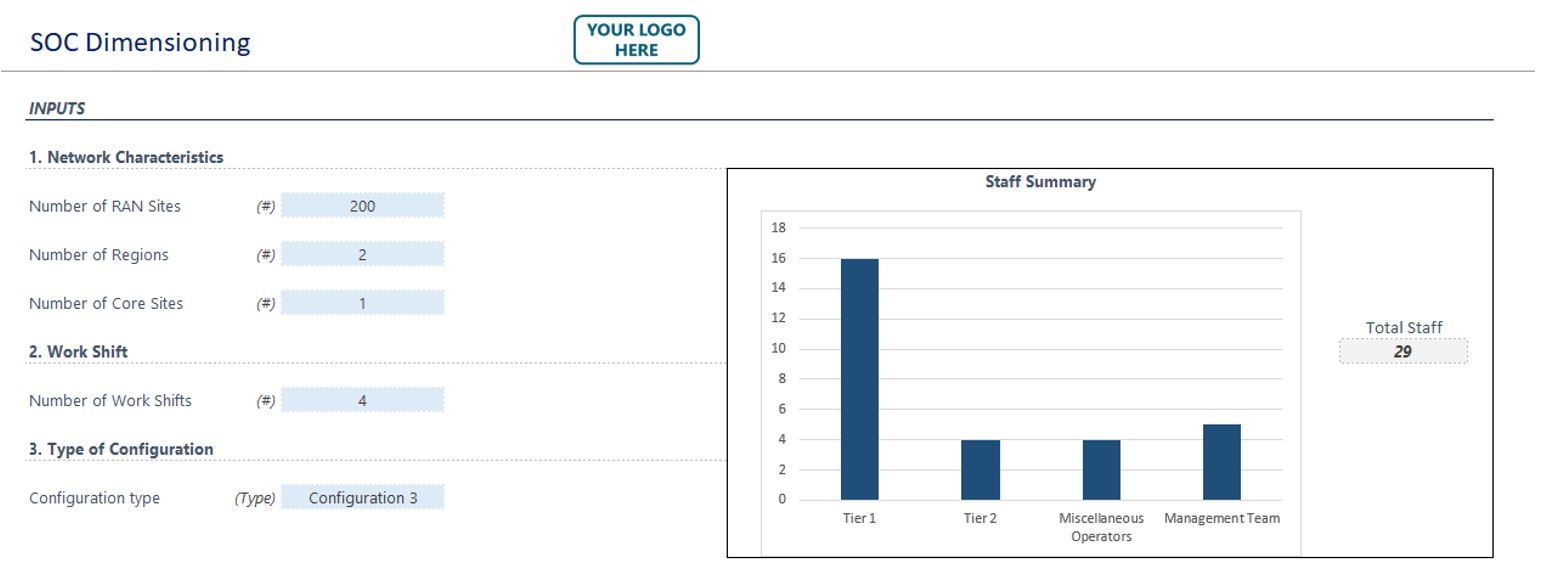
Figure 6 — SOC dimensioning tool
As mentioned earlier, the SOC is built upon a NOC solution; thus, the SOC dimensioning tool works with that consideration in place, offering both the NOC and SOC dimensioning recommendations. If the NaaS operator chooses to have a NOC solution without a SOC, they can refer to the NOC Dimensioning tool discussed on the NOC module.
Each of the inputs needs to be placed on the corresponding field. The first 3 fields (RAN sites, regions, and core sites) are open, as shown in Figure 7:
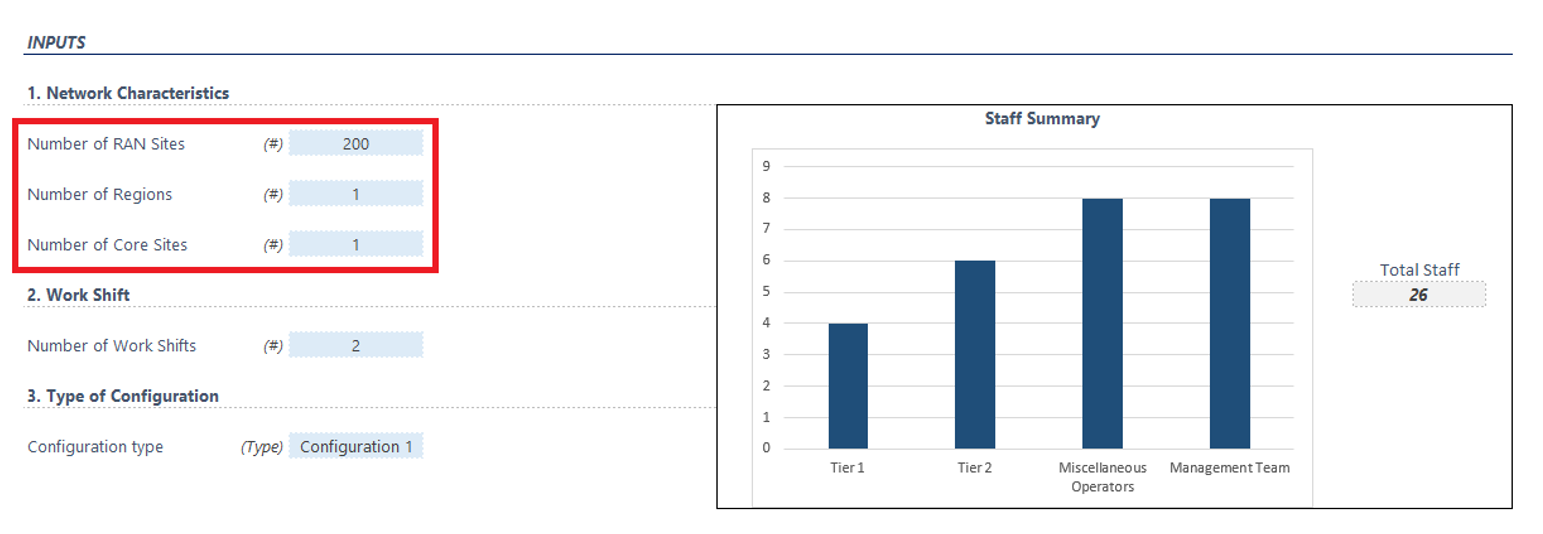
Figure 7 — Open fields in the SOC dimensioning tool
The remaining two (work shifts and configuration type) have combo boxes enabled to choose from the available options, as shown in Figure 8.
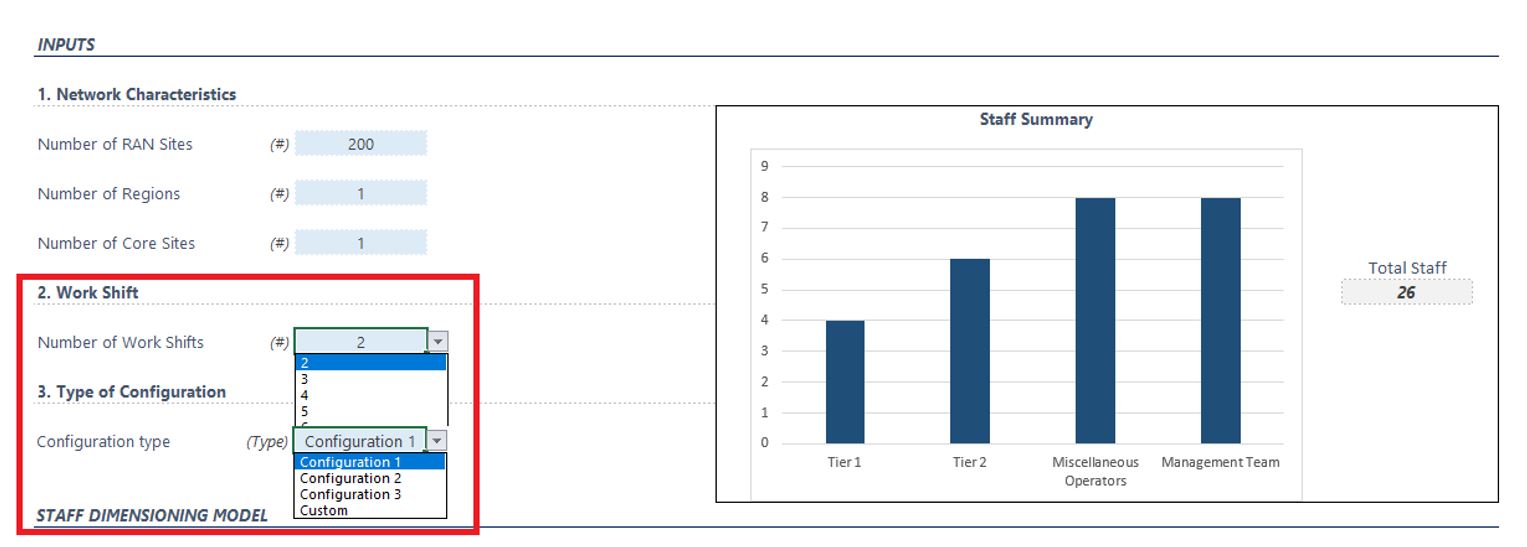
Figure 8 — Combo boxes in the SOC dimensioning tool
Once all the fields have been completed, the tool will show a brief summary at the top showing the general number of NOC and SOC staff to be considered, as shown in Figure 9:
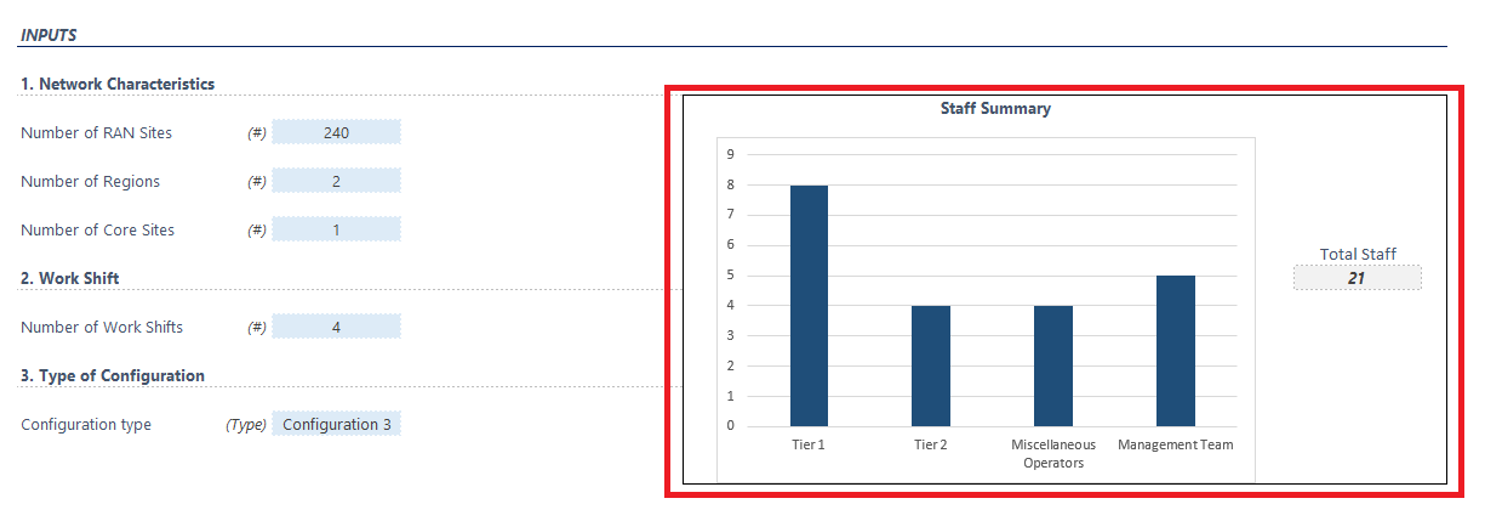
Figure 9 — Staff Summary
Then a complete list of all the resources will be presented, starting with the tier 1 and tier 2 teams (for both NOC and SOC) as shown in Figure 10.
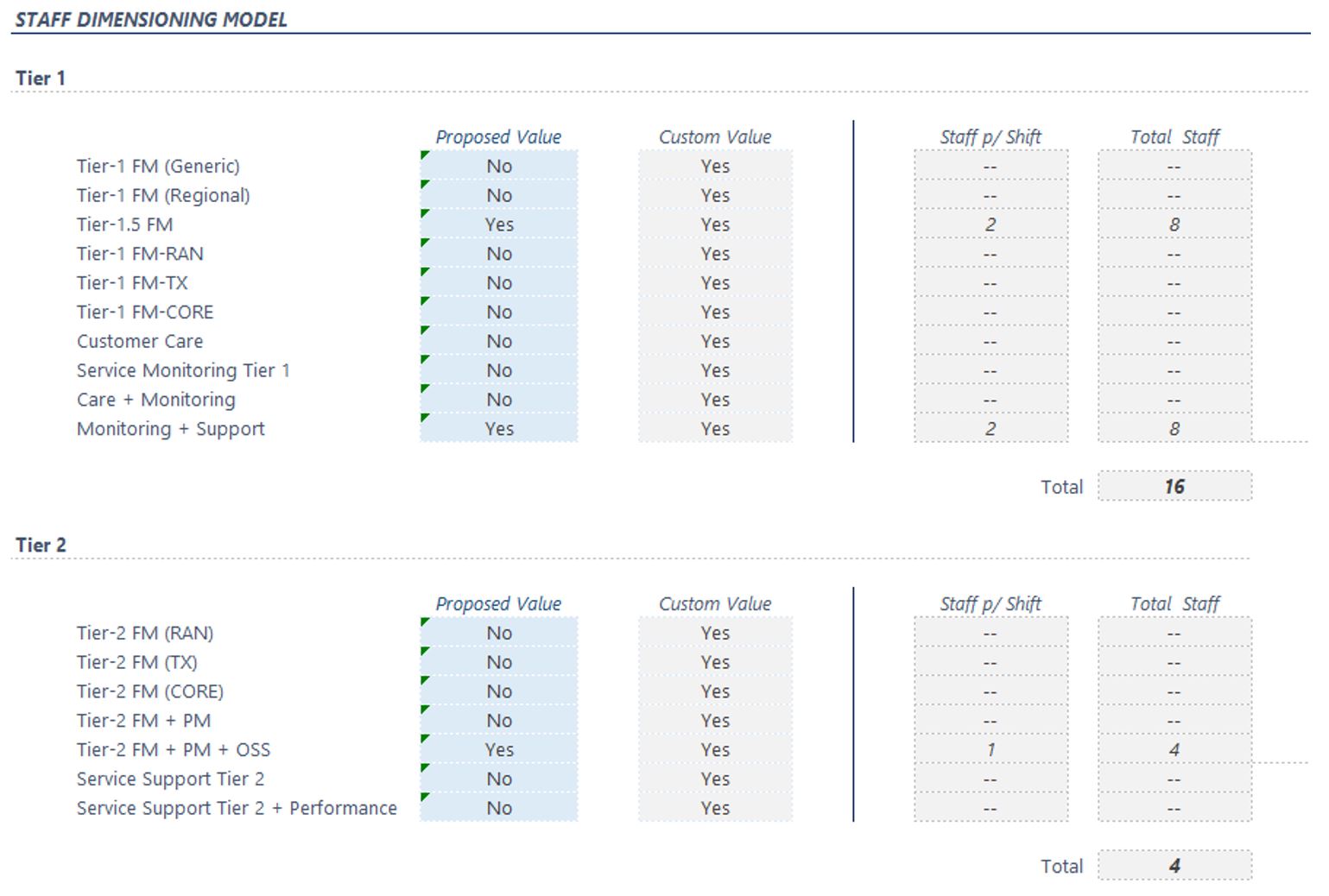
Figure 10 — Tier 1 and tier 2 resources
This is followed by the rest of the operators and the Management Team calculation, as shown in Figure 11:
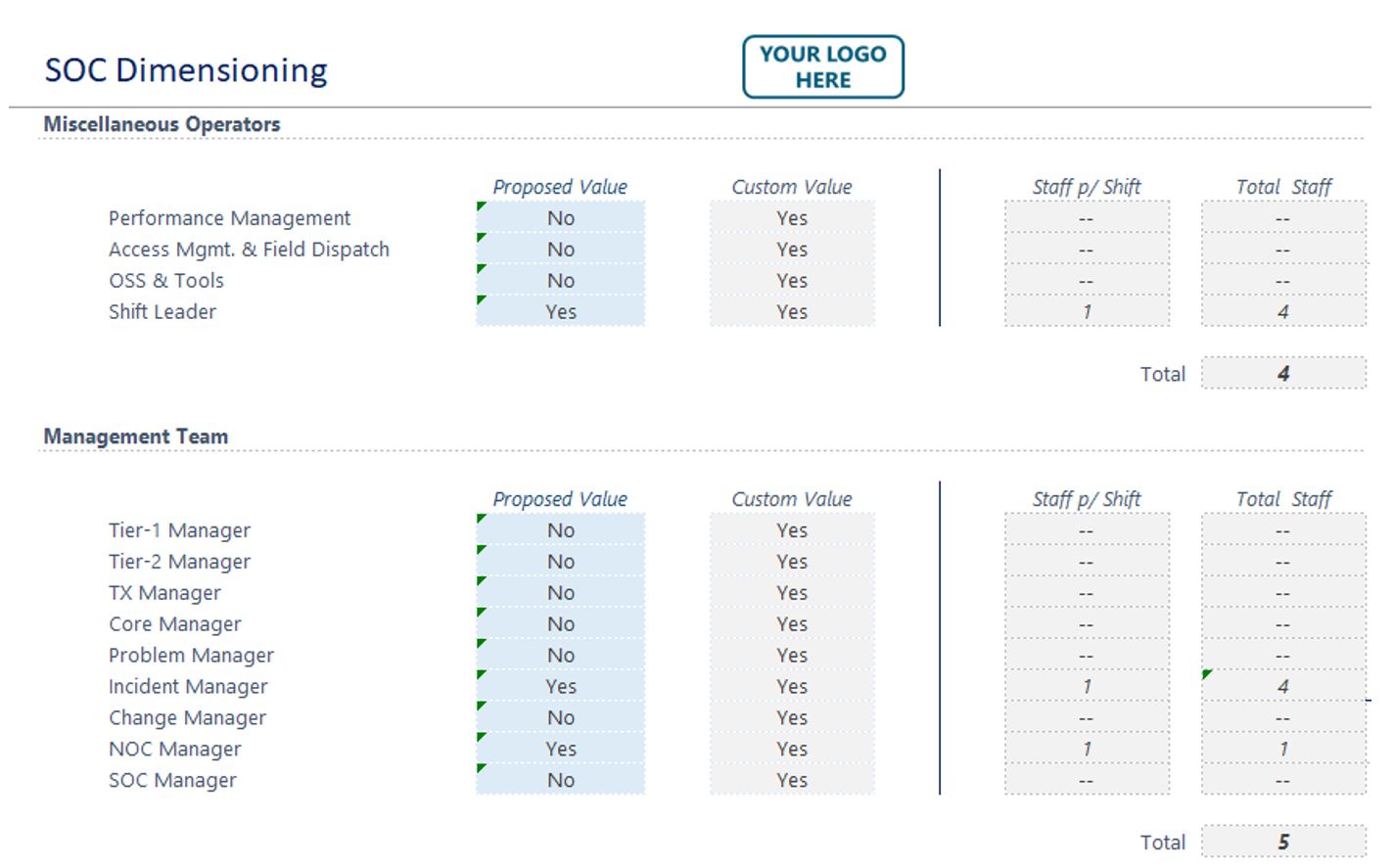
Figure 11 — Miscellaneous operators and management team
Finally, it’s worth mentioning that the tool allows for values to be customized after the initial calculus is presented, to accommodate the NaaS Operator needs.
Facility Design & Sizing
For the facilities, the operator needs to consider the peak number of resources that will be working on the NOC/SOC premises, according to the dimensioning performed on the previous section.
The SOC Dimensioning Tool can be used for facility dimensioning based on the headcount for the NOC & SOC organization, as shown in Figure 12. This works in the same way as it does for the NOC and a more detailed explanation can be found in section 6.4 of the NOC Module.
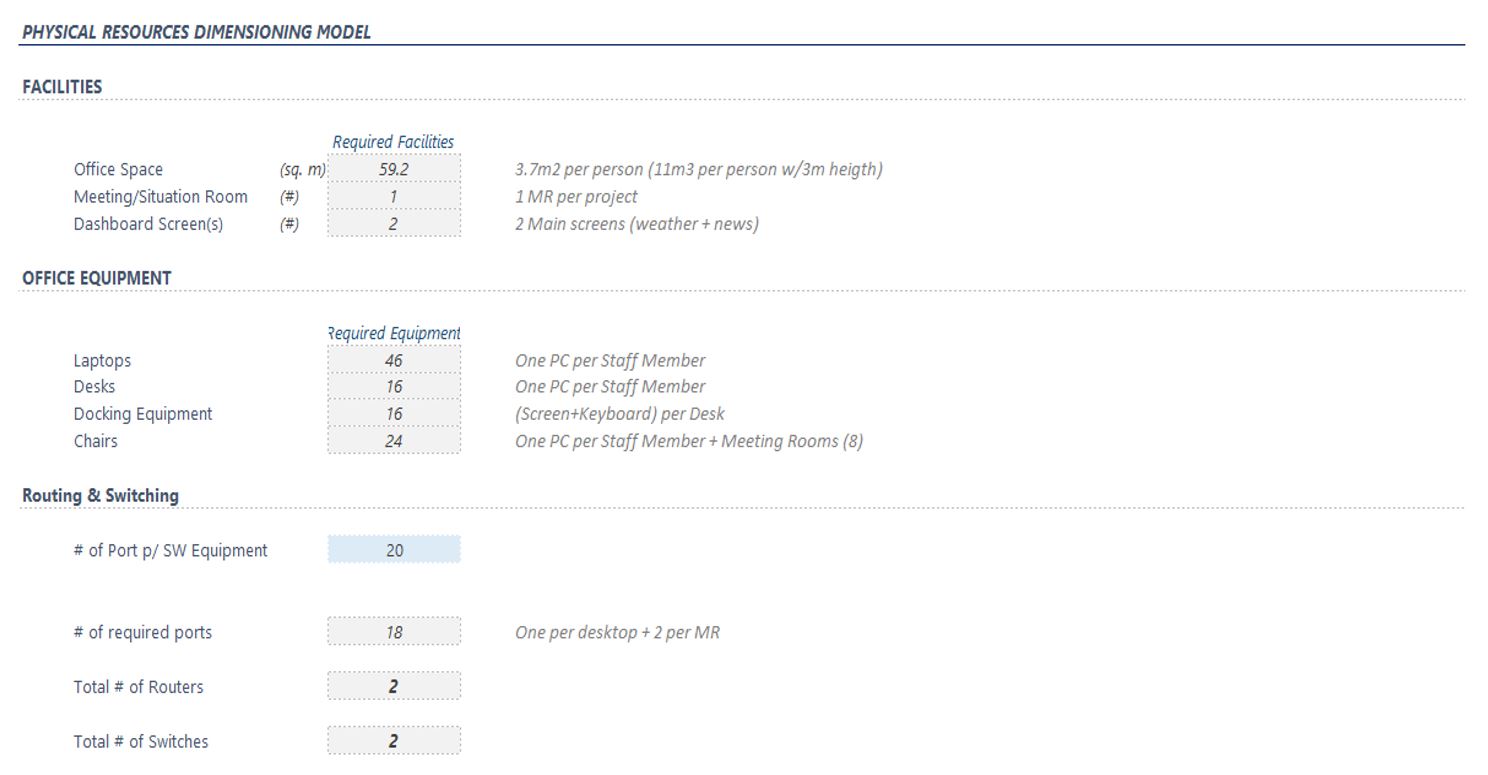
Figure 12 — SOC dimensioning tool facility sizing